Effizientes mehrstufiges Phishing-Website-Erkennungsmodell
02. März 2023 • Sicherheit

Phishing ist heute die häufigste Methode für Cyberkriminelle, um Informationen zu stehlen, und diese Cyberbedrohung wird schlimmer, da immer mehr Berichte über Datenschutzverletzungen und finanzielle Verluste durch diese Art von Cyberangriffen eingehen. Es ist wichtig zu beachten, dass die Art und Weise, wie ODS Phishing erkennt, nicht vollständig untersucht, was Phishing erfolgreich macht.
Außerdem funktionieren die Erkennungsmodelle nur gut auf einer kleinen Anzahl von Datensätzen. Sie müssen verbessert werden, bevor sie in der realen Webumgebung eingesetzt werden können. Aus diesem Grund wünschen sich Benutzer neue Möglichkeiten, um Phishing-Websites schnell und genau zu erkennen. Dafür bieten die Prinzipien des Social Engineering interessante Ansätze, die genutzt werden können, um effektive Methoden zur Erkennung von Phishing-Websites in verschiedenen Stadien zu entwickeln, insbesondere im realen Web.
Die Geschichte des Phishings
Denken Sie daran, dass Phishing eine häufige Art von Social-Engineering-Angriff ist, was bedeutet, dass Hacker die natürlichen Instinkte, das Vertrauen, die Angst und die Gier von Menschen nutzen, um sie dazu zu bringen, schlechte Dinge zu tun. Forschung zur Cybersicherheit zeigt, dass Phishing während der COVID-19-Quarantäne um 350% zugenommen hat.. Es wird angenommen, dass die Kosten für Phishing jetzt 1/4 der Kosten traditioneller Cyberangriffe ausmachen, aber die Einnahmen sind doppelt so hoch wie in der Vergangenheit. Phishing-Angriffe kosten mittelständische Unternehmen durchschnittlich $1,6 Millionen, da diese Cyberbedrohung es einfacher macht, Kunden zu verlieren, als sie zu gewinnen.
Phishing-Angriffe können unterschiedlich aussehen und verwenden normalerweise eine Reihe von Kommunikationswegen, wie E-Mail, Textnachrichten und soziale Medien. Unabhängig davon, welcher Kanal verwendet wird, geben sich Angreifer oft als bekannte Banken, Kreditkartenunternehmen oder E-Commerce-Websites aus, um Benutzer dazu zu bringen, sich auf der Phishing-Seite anzumelden und Dinge zu tun, die sie später bereuen werden, oder sie dazu zu zwingen.
Ein Benutzer könnte zum Beispiel eine Sofortnachricht erhalten, die besagt, dass es ein Problem mit seinem Bankkonto gibt, und zu einem Weblink weitergeleitet werden, der dem Link der Bank sehr ähnlich sieht. Der Benutzer zögert nicht, seinen Benutzernamen und sein Passwort in die vom Kriminellen bereitgestellten Felder einzugeben. Er notiert sich ihre Informationen, die er dann verwendet, um in die Benutzersitzung zu gelangen.
Was sollte an den Antiphishing-Methoden verbessert werden?
Um diese Frage zu beantworten, müssen wir den typischen Phishing-Prozess verstehen, der in der folgenden Abbildung dargestellt ist.
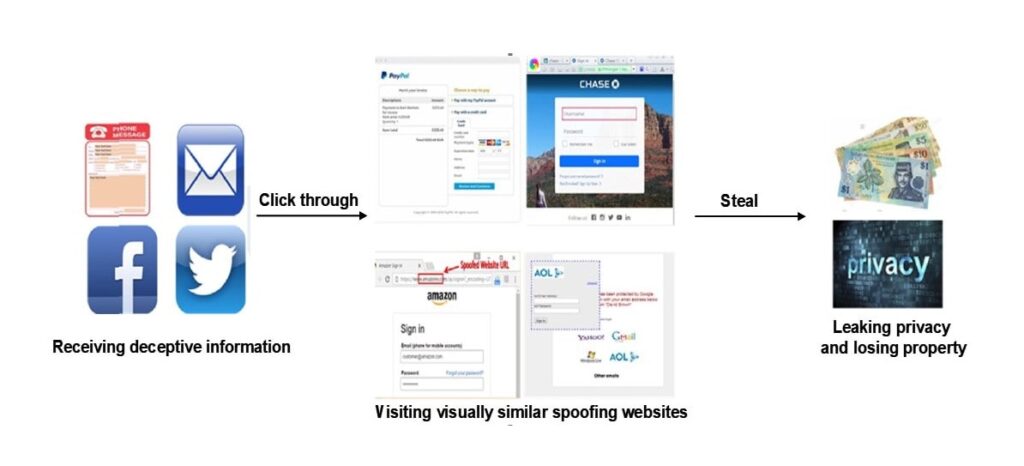
Die derzeit gängige Antiphishing-Methode ist die auf maschinellem Lernen basierende Erkennung von Phishing-Websites. Dieser Online-Erkennungsmodus, der auf statistischem Lernen basiert, ist die primäre Antiphishing-Methode; jedoch müssen ihre Robustheit und Effizienz in komplexen Webumgebungen verbessert werden. Die Hauptprobleme mit auf maschinellem Lernen basierenden Antiphishing-Methoden sind unten zusammengefasst.
• Eine zunehmende Anzahl von Merkmalen wird von Antiphishing-Methoden entfernt, aber es ist nicht klar, warum diese Merkmale entfernt werden. Bestehende Merkmale spiegeln nicht genau die Natur des Phishings wider, das Spoofing verwendet, um sensible Informationen zu stehlen. Infolgedessen werden die Funktionen nur in wenigen begrenzten und spezifischen Szenarien gültig, wie z.B. spezifische Datensätze oder ein Browser-Plugin.
• Bestehende Algorithmen behandeln alle Websites gleich, was dazu führt, dass das statistische Modell ineffizient ist. Mit anderen Worten, die Modelle sind ungeeignet für den Einsatz in einer realen Webumgebung mit einer großen Anzahl komplexer Webseiten.
• Die meisten Datensätze haben nicht genug Proben, und die Vielfalt der Proben wird nicht berücksichtigt. Außerdem ist das Verhältnis von positiven zu negativen Proben nicht realistisch. Im Allgemeinen haben Modelle, die aus solchen Datensätzen erstellt wurden, viel Overfitting, und die Robustheit der Modelle muss verbessert werden.
Was war der Fortschritt bei den Antiphishing-Methoden?
In den letzten Jahren hat man versucht, eine groß angelegte, zuverlässige und effektive Antiphishing-Methode zu entwickeln, die in einer realen Webumgebung funktioniert. Diese Methode basiert auf statistischen maschinellen Lernalgorithmen, die durch die folgenden Tests verbessert werden:
• Verwendung einer detaillierten Analyse des Musters von Phishing-Angriffen, um statistische Funktionen für Antiphishing zu finden. Die Funktionen “Fälschung”, “Zugehörigkeit”, “Diebstahl” und “Bewertung” werden von den aktuellen Modellen extrahiert. Diese werden als “CASE”-Funktionen. bezeichnet. Dieses Modell zeigt, wie Social Engineering in Phishing-Angriffen verwendet wird und wie relevant und gut der Inhalt im Web ist. Das CASE-Modell berücksichtigt die Tatsache, dass Spoofing ein Teil von Phishing ist, stellt sicher, dass Merkmale unterschieden und verallgemeinert werden können, und bietet Unterstützung auf der Merkmalsebene für eine effektive Phishing-Erkennung.
• Da legitime und Phishing-Websites nicht die gleiche Menge an Traffic haben, basieren aktuelle Erkennungsmodelle auf einem mehrstufigen Sicherheitssystem. Die Idee hinter Modellen mit mehreren Erkennungsstufen ist es, “schnelle Filterung und genaue Erkennung” zu gewährleisten. Während der schnellen Filterstufe werden legitime Websites aussortiert. Eine genaue überwachte Erkennung erfolgt dann durch das Lernen spezifischer positiver und negativer Proben in einem kleineren Bereich. Diese Philosophie der Erkennung gewährleistet eine hohe Leistung bei kürzerer Erkennungszeit, was für das reale Web realistischer ist.
• Die neuen Antiphishing-Modelle basieren darauf, Datensätze zu erstellen, die der realen Webumgebung so nahe wie möglich kommen, mit unterschiedlichen Sprachen, Inhaltsqualitäten und Marken. Da die Phishing-Erkennung ein Klassenungleichgewichtsproblem ist, wird jetzt angenommen, dass viele positive und negative Proben vermischt sind, was sie sehr schwer zu finden macht. All diese Dinge erschweren die Erkennung, um Antiphishing-Erkennungsmodelle zu erstellen, die gut funktionieren und in einer realen Webumgebung eingesetzt werden können.
Auch viele Antiphishing-Modelle arbeiten, indem sie URLs, Titel, Links, Anmeldefelder, Copyright-Informationen, vertrauliche Begriffe, Suchmaschineninformationen und sogar die Logos der Marken der Websites vergleichen, und es wurde gezeigt, dass sie zur Erkennung von Phishing-Websites verwendet werden können. In den letzten Jahren wurde mehr Aufmerksamkeit auf visuelle Spoofing-Merkmale und Bewertungsmerkmale gelegt. Aber sie waren nicht stark genug, um festzustellen, ob eine Seite eine Phishing-Seite ist.
“Mehr als 98% der Phishing-Websites verwenden gefälschte Domainnamen,” sagt die APWG. Für Antiphishing-Modelle verwenden Forscher Informationen aus der URL-Zeichenfolge. Es ist jedoch auch sehr wichtig, die Informationen hinter dem Domainnamen zu erhalten, wie z.B. Domainregistrierung und -auflösung, um Phishing zu erkennen. Diese Informationen können oft zeigen, ob ein Domainname berechtigt ist, Dienstleistungen im Zusammenhang mit einer Marke anzubieten. Daher besteht die Hauptaufgabe der Antiphishing-Forscher darin, effektive Merkmale zu finden. Sie tun dies, indem sie Social-Engineering-Angriffe untersuchen und einen vollständigen und leicht verständlichen Merkmalsrahmen vorschlagen, der nicht nur alle Aspekte von Phishing-Angriffen, sondern auch die Qualität und Relevanz von Webinhalten abdeckt.
Mehrstufige Phishing-Erkennung
Stufe 1: Whitelist-Filterung In dieser Phase werden echte Webseiten von verdächtigen anhand des Phishing-Domainnamens der Website für die Zielmarke getrennt.
Stufe 2: Dies ist die Phase des schnellen Beseitigens von gefälschten Rechnungen. Dazu gehört das Entfernen der gefälschten Titelfunktion, der gefälschten Textfunktion und der gefälschten visuellen Funktion mithilfe eines Erkennungsmodells. Der letzte Schritt besteht darin, die Funktionen der genauen Erkennung von Fälschung, Diebstahl, Zugehörigkeit, Bewertung, Training und Erkennung von Modellen mithilfe der CASE-Funktion zu extrahieren und zu kombinieren, die eine auf geänderten Modellen basierende, trainingsbasierte Phishing-Erkennung ist.
I Afslutning
Mit diesem Ansatz zur Bekämpfung von Phishing, der auf einer mehrstufigen Erkennung basiert, wird es 2022 883 Phishing-Angriffe auf China Mobile, 86 auf die Bank of China, 19 auf Facebook und 13 auf Apple geben. Dies zeigt, dass das CASE-Modell den Merkmalsraum abdeckt, der die Spoofing-Natur des Phishings widerspiegelt, sicherstellt, dass Merkmale unterschieden und verallgemeinert werden können, und effektive Unterstützung bei der Phishing-Erkennung auf der Merkmalsebene bietet.

Sicherheit
admin ist eine leitende Redakteurin für Government Technology. Zuvor schrieb sie für PYMNTS und The Bay State Banner. Sie hat einen B.A. in kreativem Schreiben von Carnegie Mellon. Sie lebt in der Nähe von Boston.