Efficient Multistage Phishing Website Detection Model
March 02, 2023 • security

Phishing is the most common method for cybercriminals to steal information today, and this cyberthreat is getting worse as more and more reports come in about privacy leaks and financial losses caused by this type of cyberattack. It’s important to keep in mind that the way ODS detects phishing doesn’t fully look at what makes phishing work.
Also, the detection models only work well on a small number of data sets. They need to be improved before they can be used in the real web environment. Because of this, users want new ways to quickly and accurately find phishing websites. For this, the principles of social engineering offer interesting points that can be used to create effective ways to spot phishing sites at different stages, especially on the real web.
The History of Phishing
Keep in mind that phishing is a common type of social engineering attack, which means that hackers use people’s natural instincts, trust, fear, and greed to trick them into doing bad things. Research on cybersecurity shows that phishing went up by 350% during the COVID-19 quarantine. It is thought that the cost of phishing is now 1/4 of the cost of traditional cyberattacks, but the revenue is double what it was in the past. Phishing attacks cost midsize businesses an average of $1.6 million to deal with because this cyberthreat makes it easier to lose customers than to gain them.
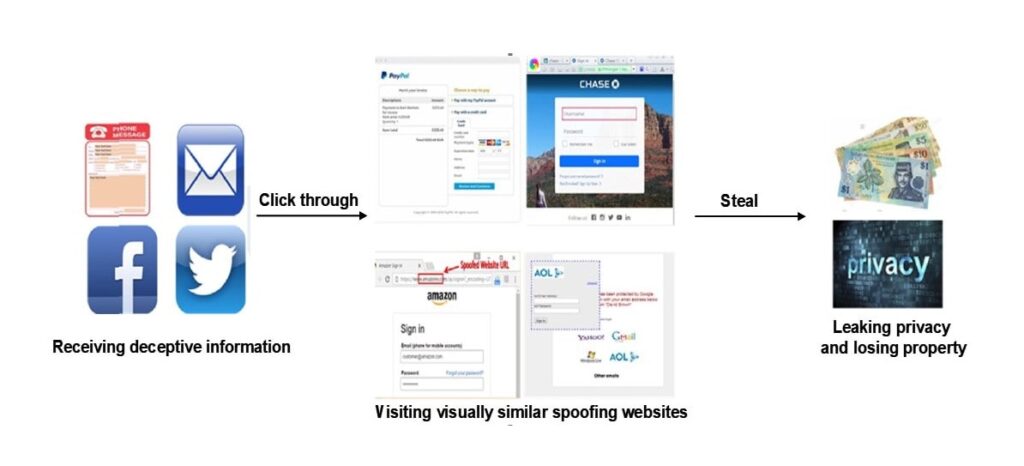
Phishing attacks can look different and usually use a number of ways to talk to people, like email, text messages, and social media. No matter what channel is used, attackers often pretend to be well-known banks, credit card companies, or e-commerce sites to scare users into logging into the phishing site and doing things they will later regret, or to force them to do so.
For example, a user might again get an instant message saying there’s a problem with their bank account and be sent to a web link that looks a lot like the link the bank uses. The user doesn’t think twice about putting his username and password into the fields that the criminal gives him. He makes a note of her information, which he then uses to get into the user’s session.
What should be improved in Antiphising methods?
To answer this question, we must understand the typical phishing process, which is shown in the following figure.
The current mainstream antiphishing method is machine learning-based phishing website detection. This online detection mode, which is based on statistical learning, is the primary antiphishing method; however, its robustness and efficiency in complex web environments must be improved. The main issues with machine learning-based antiphishing methods are summarized below.
• An increasing number of features are being removed by antiphishing methods, but it is not clear why these features are being removed. Existing features do not accurately reflect the nature of phishing, which uses spoofing to steal sensitive information. As a result, the functions become valid only in a few limited and specific scenarios, such as specific data sets or a browser plugin.
• Existing algorithms treat all websites the same way, resulting in the statistical model being inefficient. In other words, the models are unsuitable for use in a real-world web environment with a large number of complex web pages.
• Most data sets don’t have enough samples, and the diversity of the samples isn’t taken into account. Also, the ratio of positive to negative samples isn’t realistic. In general, models built from these kinds of data sets have a lot of overfitting, and the models’ robustness needs to be improved.
What has been the advance in Antiphishing methods?
In the past few years, people have tried to come up with a large-scale, reliable, and effective anti-phishing method that works in a real web environment. This method is based on statistical machine learning algorithms that are improved by the following tests:
• Using a detailed analysis of the pattern of phishing attacks to find statistical functions for anti-phishing. The functions “counterfeit,” “affiliation,” “theft,” and “assessment” are all extracted by the current models. These are called “CASE” functions. This model shows how social engineering is used in phishing attacks and how relevant and good the content is on the web. The CASE model takes into account the fact that spoofing is a part of phishing, makes sure that features can be distinguished and generalized, and provides support at the feature level for effective phishing detection.
• Because legitimate and phishing websites don’t have the same amount of traffic, current detection models are based on a multi-stage security system. The idea behind models with multiple stages of detection is to ensure “fast filtering and accurate recognition.” During the quick filter stage, legitimate websites are weeded out. Accurate supervised recognition is then done by learning specific positive and negative samples in a smaller range. This philosophy of detection ensures high performance with a shorter detection time, which is more realistic for the real web.
• The new Antiphishing models are based on building data sets that are as close as possible to the real web environment, with different languages, content qualities, and brands. Also, since Phishing detection is a class imbalance problem, a lot of positive and negative samples are now thought to be mixed up, which makes them very hard to find. All of these things make it harder to find in order to make Antiphishing detection models that work well and can be used in a real web environment.
Even many Antiphishing models work by comparing URLs, titles, links, login boxes, copyright information, confidential terms, search engine information, and even the logos of the websites’ brands, and it has been shown that they can be used to find phishing websites. In the past few years, more attention has been paid to visual spoofing features and evaluation features. But they haven’t been strong enough to tell if a site is a Phishing site.
“More than 98% of phishing websites use fake domain names,” says the APWG. For antiphishing models, researchers use information from the URL string. However, getting the information behind the domain name, such as domain registration and resolution, is also very important for phishing detection. This information can often show if a domain name is allowed to offer services related to a brand. So, the main job of antiphishing researchers is to find effective features. They do this by looking at social engineering attacks and proposing a complete and easy-to-understand feature framework that covers not only all aspects of phishing attacks but also the quality and relevance of web content.
Multistage phishing detection
Stage 1: White-list filtering At this stage, real web pages are separated from suspicious ones based on the phishing domain name of the website for the target brand.
Stage 2: This is the stage of quickly getting rid of fake bills. This includes getting rid of the fake title function, the fake text function, and the fake visual function using a detection model. The last step is to extract and combine the functions of accurate recognition of counterfeit, theft, affiliation, evaluation, training, and detection of models using the CASE function, which is a training-based phishing detection based on changed models.
Conclusion
With this approach to stopping phishing, which is based on multi-scale detection, there will be 883 phishing attacks on China Mobile, 86 on Bank of China, 19 on Facebook, and 13 on Apple in 2022. demonstrating that the CASE model covers the feature space that reflects the spoofing nature of phishing, making sure that features can be distinguished and generalized, and giving effective phishing detection support at the feature level.

security
admin is a senior staff writer for Government Technology. She previously wrote for PYMNTS and The Bay State Banner, and holds a B.A. in creative writing from Carnegie Mellon. She’s based outside Boston.