効率的な多段階フィッシングウェブサイト検出モデル
2023年3月02日 • セキュリティ

Phishing is the most common method for cybercriminals to steal information today, and this cyberthreat is getting worse as more and more reports come in about privacy leaks and financial losses caused by this type of cyberattack. It’s important to keep in mind that the way ODS detects phishing doesn’t fully look at what makes phishing work.
また、検出モデルは少数のデータセットでしかうまく機能しません。実際のウェブ環境で使用する前に改善が必要です。このため、ユーザーはフィッシングサイトを迅速かつ正確に見つける新しい方法を求めています。これには、社会工学の原則が、特に実際のウェブ上で、異なる段階でフィッシングサイトを見つける効果的な方法を作成するために使用できる興味深いポイントを提供します。.
フィッシングの歴史
Keep in mind that phishing is a common type of social engineering attack, which means that hackers use people’s natural instincts, trust, fear, and greed to trick them into doing bad things. Research on cybersecurity shows that COVID-19の隔離期間中にフィッシングが350%増加しました. フィッシングのコストは現在、従来のサイバー攻撃のコストの1/4と考えられていますが、収益は過去の2倍です。フィッシング攻撃は、中規模企業に平均1.6百万ドルのコストをかけます。これは、このサイバー脅威が顧客を獲得するよりも失うことを容易にするためです。.
フィッシング攻撃は異なる見え方をすることがあり、通常、メール、テキストメッセージ、ソーシャルメディアなど、さまざまな方法で人々とコミュニケーションをとります。どのチャネルが使用されても、攻撃者はしばしば有名な銀行、クレジットカード会社、またはeコマースサイトを装い、ユーザーをフィッシングサイトにログインさせて後悔する行動を取らせるか、強制的に行動させます。.
For example, a user might again get an instant message saying there’s a problem with their bank account and be sent to a web link that looks a lot like the link the bank uses. The user doesn’t think twice about putting his username and password into the fields that the criminal gives him. He makes a note of her information, which he then uses to get into the user’s session.
アンチフィッシング手法で改善すべき点は何ですか?
この質問に答えるためには、次の図に示されている典型的なフィッシングプロセスを理解する必要があります。.
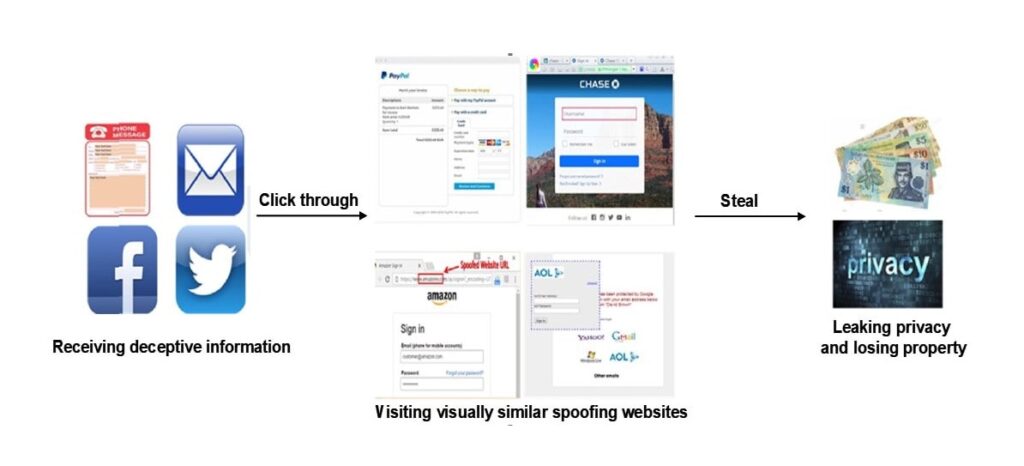
現在の主流のアンチフィッシング手法は、機械学習に基づくフィッシングサイト検出です。このオンライン検出モードは、統計的学習に基づいており、主要なアンチフィッシング手法ですが、複雑なウェブ環境での堅牢性と効率を向上させる必要があります。機械学習に基づくアンチフィッシング手法の主な問題点は以下にまとめられています。.
• アンチフィッシング手法によって削除される特徴の数が増えていますが、これらの特徴が削除される理由は明確ではありません。既存の特徴は、機密情報を盗むために偽装を使用するフィッシングの本質を正確に反映していません。その結果、機能は特定のデータセットやブラウザプラグインなど、限られた特定のシナリオでのみ有効になります。.
• 既存のアルゴリズムはすべてのウェブサイトを同じように扱い、統計モデルが非効率になります。つまり、多数の複雑なウェブページを持つ実際のウェブ環境での使用には不適切です。.
• Most data sets don’t have enough samples, and the diversity of the samples isn’t taken into account. Also, the ratio of positive to negative samples isn’t realistic. In general, models built from these kinds of data sets have a lot of overfitting, and the models’ robustness needs to be improved.
アンチフィッシング手法の進展は何ですか?
過去数年間で、人々は実際のウェブ環境で機能する大規模で信頼性があり効果的なアンチフィッシング手法を考案しようとしました。この手法は、以下のテストによって改善された統計的機械学習アルゴリズムに基づいています。
• Using a detailed analysis of the pattern of phishing attacks to find statistical functions for anti-phishing. The functions “counterfeit,” “affiliation,” “theft,” and “assessment” are all extracted by the current models. These are called “CASE” functions. このモデルは、フィッシング攻撃で社会工学がどのように使用されているか、ウェブ上のコンテンツの関連性と質の良さを示しています。CASEモデルは、フィッシングの一部である偽装を考慮し、特徴が区別され一般化できることを保証し、効果的なフィッシング検出のための特徴レベルでのサポートを提供します。.
• Because legitimate and phishing websites don’t have the same amount of traffic, current detection models are based on a multi-stage security system. The idea behind models with multiple stages of detection is to ensure “fast filtering and accurate recognition.” During the quick filter stage, legitimate websites are weeded out. Accurate supervised recognition is then done by learning specific positive and negative samples in a smaller range. This philosophy of detection ensures high performance with a shorter detection time, which is more realistic for the real web.
• 新しいアンチフィッシングモデルは、異なる言語、コンテンツの質、ブランドを持つ実際のウェブ環境にできるだけ近いデータセットを構築することに基づいています。また、フィッシング検出はクラス不均衡問題であるため、多くの正と負のサンプルが混同されていると考えられており、非常に見つけにくくなっています。これらすべての要素が、実際のウェブ環境で機能しうるアンチフィッシング検出モデルを作成することを困難にしています。.
Even many Antiphishing models work by comparing URLs, titles, links, login boxes, copyright information, confidential terms, search engine information, and even the logos of the websites’ brands, and it has been shown that they can be used to find phishing websites. In the past few years, more attention has been paid to visual spoofing features and evaluation features. But they haven’t been strong enough to tell if a site is a Phishing site.
“98%以上のフィッシングサイトが偽のドメイン名を使用しています,” APWGによると。アンチフィッシングモデルの研究者は、URL文字列からの情報を使用します。しかし、ドメイン名の背後にある情報、例えばドメイン登録と解決は、フィッシング検出にとって非常に重要です。この情報はしばしば、ドメイン名がブランドに関連するサービスを提供することを許可されているかどうかを示すことができます。したがって、アンチフィッシング研究者の主な仕事は、効果的な特徴を見つけることです。彼らは社会工学攻撃を調査し、フィッシング攻撃のすべての側面だけでなく、ウェブコンテンツの質と関連性もカバーする完全で理解しやすい特徴フレームワークを提案します。.
多段階フィッシング検出
ステージ1: ホワイトリストフィルタリング この段階では、ターゲットブランドのフィッシングドメイン名に基づいて、実際のウェブページと疑わしいものを分離します。.
ステージ2: これは偽の請求書を迅速に排除する段階です。これには、検出モデルを使用して偽のタイトル機能、偽のテキスト機能、偽のビジュアル機能を排除することが含まれます。最後のステップは、CASE機能を使用したトレーニングベースのフィッシング検出に基づく変更されたモデルを使用して、偽造、盗難、提携、評価、トレーニング、モデルの検出の正確な認識の機能を抽出し、組み合わせることです。.
結論
マルチスケール検出に基づくこのフィッシング防止アプローチにより、2022年にはChina Mobileで883件、Bank of Chinaで86件、Facebookで19件、Appleで13件のフィッシング攻撃が発生しました。CASEモデルがフィッシングの偽装の性質を反映する特徴空間をカバーし、特徴が区別され一般化できることを保証し、特徴レベルで効果的なフィッシング検出サポートを提供することを示しています。.

セキュリティ
ガバメント・テクノロジー誌のシニア・スタッフ・ライター。以前はPYMNTSとThe Bay State Bannerに寄稿し、カーネギーメロン大学でクリエイティブ・ライティングの学士号を取得。ボストン郊外に拠点を置く。