효율적인 다단계 피싱 웹사이트 탐지 모델
2023년 3월 2일 • 보안

Phishing is the most common method for cybercriminals to steal information today, and this cyberthreat is getting worse as more and more reports come in about privacy leaks and financial losses caused by this type of cyberattack. It’s important to keep in mind that the way ODS detects phishing doesn’t fully look at what makes phishing work.
또한, 탐지 모델은 소수의 데이터 세트에서만 잘 작동합니다. 실제 웹 환경에서 사용되기 전에 개선이 필요합니다. 이 때문에 사용자들은 피싱 웹사이트를 빠르고 정확하게 찾을 수 있는 새로운 방법을 원합니다. 이를 위해 사회 공학의 원칙은 특히 실제 웹에서 피싱 사이트를 다양한 단계에서 효과적으로 감지할 수 있는 흥미로운 포인트를 제공합니다.
피싱의 역사
Keep in mind that phishing is a common type of social engineering attack, which means that hackers use people’s natural instincts, trust, fear, and greed to trick them into doing bad things. Research on cybersecurity shows that COVID-19 격리 기간 동안 피싱이 350% 증가했습니다.. 피싱의 비용은 이제 전통적인 사이버 공격 비용의 1/4로 추정되지만, 수익은 과거의 두 배입니다. 피싱 공격은 중간 규모의 기업에 평균 $1.6백만 달러의 비용을 초래하며, 이 사이버 위협은 고객을 잃기 쉽게 만듭니다.
피싱 공격은 다양한 형태로 나타날 수 있으며, 이메일, 문자 메시지, 소셜 미디어와 같은 여러 가지 방법을 사용하여 사람들과 소통합니다. 어떤 채널을 사용하든 공격자들은 종종 유명한 은행, 신용 카드 회사, 또는 전자 상거래 사이트로 가장하여 사용자가 피싱 사이트에 로그인하고 후회할 행동을 하도록 유도하거나 강요합니다.
For example, a user might again get an instant message saying there’s a problem with their bank account and be sent to a web link that looks a lot like the link the bank uses. The user doesn’t think twice about putting his username and password into the fields that the criminal gives him. He makes a note of her information, which he then uses to get into the user’s session.
안티피싱 방법에서 개선되어야 할 점은 무엇인가요?
이 질문에 답하기 위해서는 다음 그림에 나타난 전형적인 피싱 과정을 이해해야 합니다.
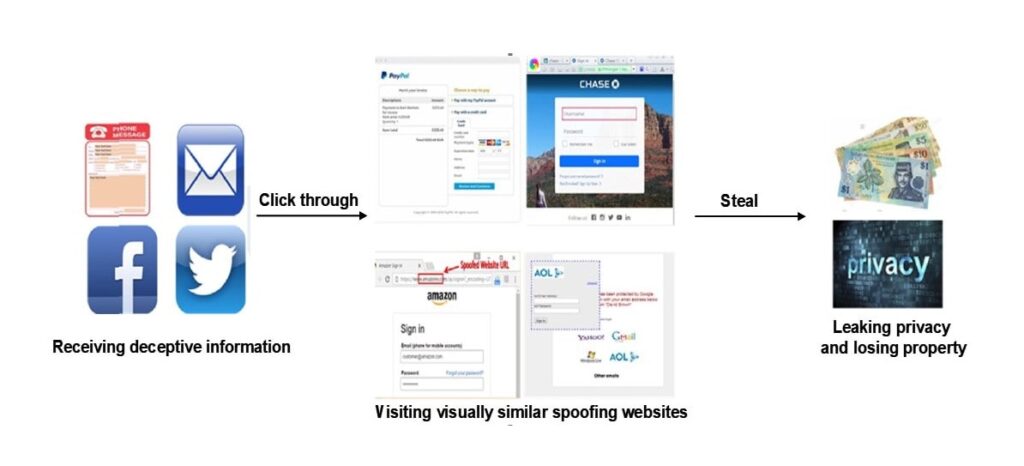
현재 주류 안티피싱 방법은 머신 러닝 기반의 피싱 웹사이트 탐지입니다. 통계적 학습에 기반한 이 온라인 탐지 모드는 주요 안티피싱 방법이지만, 복잡한 웹 환경에서의 강건성과 효율성이 개선되어야 합니다. 머신 러닝 기반 안티피싱 방법의 주요 문제점은 아래에 요약되어 있습니다.
• 안티피싱 방법에 의해 점점 더 많은 기능이 제거되고 있지만, 이러한 기능이 왜 제거되는지는 명확하지 않습니다. 기존 기능은 민감한 정보를 훔치기 위해 스푸핑을 사용하는 피싱의 본질을 정확하게 반영하지 않습니다. 결과적으로 기능은 특정 데이터 세트나 브라우저 플러그인과 같은 제한적이고 특정한 시나리오에서만 유효합니다.
• 기존 알고리즘은 모든 웹사이트를 동일하게 취급하여 통계 모델이 비효율적입니다. 즉, 많은 수의 복잡한 웹 페이지가 있는 실제 웹 환경에서 사용하기에 모델이 적합하지 않습니다.
• Most data sets don’t have enough samples, and the diversity of the samples isn’t taken into account. Also, the ratio of positive to negative samples isn’t realistic. In general, models built from these kinds of data sets have a lot of overfitting, and the models’ robustness needs to be improved.
안티피싱 방법의 발전은 무엇인가요?
지난 몇 년 동안 사람들은 실제 웹 환경에서 작동하는 대규모, 신뢰할 수 있고 효과적인 안티피싱 방법을 개발하려고 노력했습니다. 이 방법은 다음 테스트에 의해 개선된 통계적 머신 러닝 알고리즘에 기반합니다.
• Using a detailed analysis of the pattern of phishing attacks to find statistical functions for anti-phishing. The functions “counterfeit,” “affiliation,” “theft,” and “assessment” are all extracted by the current models. These are called “CASE” functions. 이 모델은 피싱 공격에서 사회 공학이 어떻게 사용되는지와 웹에서의 관련성과 콘텐츠의 품질을 보여줍니다. CASE 모델은 피싱의 일부인 스푸핑을 고려하여 기능을 구별하고 일반화할 수 있도록 하며, 효과적인 피싱 탐지를 위한 기능 수준의 지원을 제공합니다.
• Because legitimate and phishing websites don’t have the same amount of traffic, current detection models are based on a multi-stage security system. The idea behind models with multiple stages of detection is to ensure “fast filtering and accurate recognition.” During the quick filter stage, legitimate websites are weeded out. Accurate supervised recognition is then done by learning specific positive and negative samples in a smaller range. This philosophy of detection ensures high performance with a shorter detection time, which is more realistic for the real web.
• 새로운 안티피싱 모델은 실제 웹 환경에 최대한 가까운 데이터 세트를 구축하는 데 기반을 두고 있으며, 다양한 언어, 콘텐츠 품질, 브랜드를 포함합니다. 또한, 피싱 탐지가 클래스 불균형 문제이기 때문에 많은 긍정적 및 부정적 샘플이 혼합되어 매우 찾기 어렵다고 생각됩니다. 이러한 모든 요소는 실제 웹 환경에서 잘 작동하고 사용할 수 있는 안티피싱 탐지 모델을 만드는 것을 어렵게 합니다.
Even many Antiphishing models work by comparing URLs, titles, links, login boxes, copyright information, confidential terms, search engine information, and even the logos of the websites’ brands, and it has been shown that they can be used to find phishing websites. In the past few years, more attention has been paid to visual spoofing features and evaluation features. But they haven’t been strong enough to tell if a site is a Phishing site.
“98% 이상의 피싱 웹사이트가 가짜 도메인 이름을 사용합니다.,” APWG에 따르면, 안티피싱 모델을 위해 연구자들은 URL 문자열에서 정보를 사용합니다. 그러나 도메인 등록 및 해상도와 같은 도메인 이름 뒤의 정보를 얻는 것도 피싱 탐지에 매우 중요합니다. 이 정보는 종종 도메인 이름이 브랜드와 관련된 서비스를 제공할 수 있는지 여부를 보여줄 수 있습니다. 따라서 안티피싱 연구자들의 주요 임무는 효과적인 기능을 찾는 것입니다. 그들은 사회 공학 공격을 조사하고 피싱 공격의 모든 측면뿐만 아니라 웹 콘텐츠의 품질과 관련성을 포괄하는 완전하고 이해하기 쉬운 기능 프레임워크를 제안합니다.
다단계 피싱 탐지
단계 1: 화이트리스트 필터링 이 단계에서는 웹사이트의 피싱 도메인 이름을 기반으로 실제 웹 페이지와 의심스러운 웹 페이지를 분리합니다.
단계 2: 가짜 청구서를 빠르게 제거하는 단계입니다. 여기에는 탐지 모델을 사용하여 가짜 제목 기능, 가짜 텍스트 기능, 가짜 시각적 기능을 제거하는 것이 포함됩니다. 마지막 단계는 변경된 모델에 기반한 훈련 기반 피싱 탐지인 CASE 기능을 사용하여 정확한 인식, 도난, 제휴, 평가, 훈련 및 모델 탐지의 기능을 추출하고 결합하는 것입니다.
결론적으로
다단계 탐지에 기반한 이 피싱 방지 접근 방식으로 2022년에는 중국 모바일에서 883건, 중국 은행에서 86건, 페이스북에서 19건, 애플에서 13건의 피싱 공격이 발생할 것입니다. 이는 CASE 모델이 피싱의 스푸핑 본질을 반영하는 기능 공간을 포괄하고, 기능을 구별하고 일반화할 수 있도록 하며, 기능 수준에서 효과적인 피싱 탐지 지원을 제공함을 보여줍니다.

보안
admin은 정부 기술의 선임 스태프 작가입니다. 이전에는 PYMNTS와 베이 스테이트 배너에 글을 썼으며 카네기 멜론에서 문예창작 학사 학위를 받았습니다. 현재 보스턴 외곽에 거주하고 있습니다.