Model eficient de detectare a site-urilor Phishing în mai multe etape
martie 02, 2023 • securitate

Phishingul este cea mai comună metodă prin care infractorii cibernetici fură informații astăzi, iar această amenințare cibernetică se înrăutățește pe măsură ce tot mai multe rapoarte apar despre scurgeri de confidențialitate și pierderi financiare cauzate de acest tip de atac cibernetic. Este important să ținem cont de faptul că modul în care ODS detectează phishingul nu analizează pe deplin ceea ce face ca phishingul să funcționeze.
De asemenea, modelele de detectare funcționează bine doar pe un număr mic de seturi de date. Ele trebuie îmbunătățite înainte de a putea fi utilizate în mediul real de web. Din acest motiv, utilizatorii doresc noi modalități de a găsi rapid și precis site-urile de phishing. Pentru aceasta, principiile ingineriei sociale oferă puncte interesante care pot fi folosite pentru a crea modalități eficiente de a identifica site-urile de phishing în diferite etape, în special pe web-ul real.
Istoria Phishingului
Țineți cont de faptul că phishingul este un tip comun de atac de inginerie socială, ceea ce înseamnă că hackerii folosesc instinctele naturale, încrederea, frica și lăcomia oamenilor pentru a-i păcăli să facă lucruri rele. Cercetările în domeniul securității cibernetice arată că phishingul a crescut cu 350% în timpul carantinei COVID-19. Se crede că costul phishingului este acum 1/4 din costul atacurilor cibernetice tradiționale, dar veniturile sunt duble față de cele din trecut. Atacurile de phishing costă companiile de dimensiuni medii în medie $1,6 milioane de dolari pentru a le gestiona, deoarece această amenințare cibernetică face mai ușor să pierzi clienți decât să-i câștigi.
Atacurile de phishing pot arăta diferit și de obicei folosesc o serie de modalități de a comunica cu oamenii, cum ar fi e-mailul, mesajele text și rețelele sociale. Indiferent de canalul utilizat, atacatorii se prefac adesea a fi bănci cunoscute, companii de carduri de credit sau site-uri de comerț electronic pentru a speria utilizatorii să se conecteze la site-ul de phishing și să facă lucruri pe care le vor regreta mai târziu sau pentru a-i forța să facă acest lucru.
De exemplu, un utilizator ar putea primi din nou un mesaj instantaneu care spune că există o problemă cu contul său bancar și să fie trimis la un link web care seamănă foarte mult cu linkul folosit de bancă. Utilizatorul nu se gândește de două ori înainte de a introduce numele de utilizator și parola în câmpurile oferite de criminal. El notează informațiile ei, pe care le folosește apoi pentru a accesa sesiunea utilizatorului.
Ce ar trebui îmbunătățit în metodele de Antiphishing?
Pentru a răspunde la această întrebare, trebuie să înțelegem procesul tipic de phishing, care este prezentat în figura următoare.
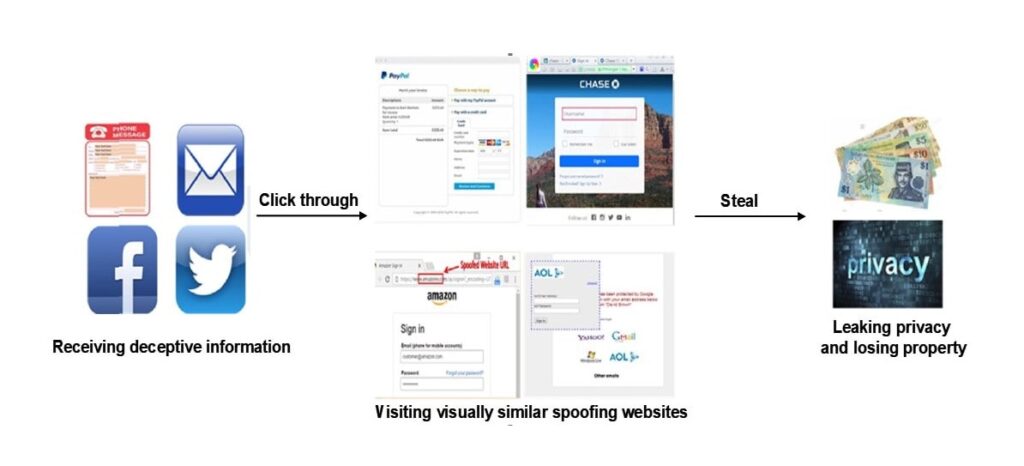
Metoda actuală principală de antiphishing este detectarea site-urilor de phishing bazată pe învățarea automată. Acest mod de detectare online, care se bazează pe învățarea statistică, este metoda principală de antiphishing; cu toate acestea, robustețea și eficiența sa în medii web complexe trebuie îmbunătățite. Problemele principale cu metodele de antiphishing bazate pe învățarea automată sunt rezumate mai jos.
• Un număr tot mai mare de caracteristici sunt eliminate de metodele de antiphishing, dar nu este clar de ce aceste caracteristici sunt eliminate. Caracteristicile existente nu reflectă cu acuratețe natura phishingului, care folosește înșelăciunea pentru a fura informații sensibile. Drept urmare, funcțiile devin valabile doar în câteva scenarii limitate și specifice, cum ar fi seturi de date specifice sau un plugin de browser.
• Algoritmii existenți tratează toate site-urile web în același mod, rezultând într-un model statistic ineficient. Cu alte cuvinte, modelele nu sunt potrivite pentru utilizarea într-un mediu web real cu un număr mare de pagini web complexe.
• Majoritatea seturilor de date nu au suficiente mostre, iar diversitatea mostrelor nu este luată în considerare. De asemenea, raportul dintre mostrele pozitive și cele negative nu este realist. În general, modelele construite din aceste tipuri de seturi de date au mult overfitting, iar robustețea modelelor trebuie îmbunătățită.
Care a fost progresul în metodele de Antiphishing?
În ultimii ani, s-a încercat dezvoltarea unei metode de antiphishing la scară largă, fiabilă și eficientă, care să funcționeze într-un mediu web real. Această metodă se bazează pe algoritmi de învățare automată statistică care sunt îmbunătățiți prin următoarele teste:
• Folosirea unei analize detaliate a tiparului atacurilor de phishing pentru a găsi funcții statistice pentru antiphishing. Funcțiile “contrafacere”, “afiliere”, “furt” și “evaluare” sunt toate extrase de modelele actuale. Acestea sunt numite “funcții ”CASE”. Acest model arată cum este utilizată ingineria socială în atacurile de phishing și cât de relevant și bun este conținutul pe web. Modelul CASE ia în considerare faptul că înșelăciunea este o parte a phishingului, asigură că caracteristicile pot fi distinse și generalizate și oferă suport la nivel de caracteristică pentru detectarea eficientă a phishingului.
• Deoarece site-urile web legitime și cele de phishing nu au același volum de trafic, modelele actuale de detectare se bazează pe un sistem de securitate multietapă. Ideea din spatele modelelor cu mai multe etape de detectare este de a asigura “filtrarea rapidă și recunoașterea precisă”. În timpul etapei de filtrare rapidă, site-urile web legitime sunt eliminate. Recunoașterea supravegheată precisă este apoi realizată prin învățarea unor mostre pozitive și negative specifice într-un interval mai mic. Această filozofie de detectare asigură o performanță ridicată cu un timp de detectare mai scurt, ceea ce este mai realist pentru web-ul real.
• Noile modele de Antiphishing se bazează pe construirea de seturi de date care sunt cât mai aproape posibil de mediul web real, cu limbi diferite, calități de conținut și mărci. De asemenea, deoarece detectarea phishingului este o problemă de dezechilibru de clasă, acum se consideră că multe mostre pozitive și negative sunt amestecate, ceea ce le face foarte greu de găsit. Toate aceste lucruri fac mai dificilă găsirea pentru a crea modele de detectare a Antiphishingului care să funcționeze bine și să poată fi utilizate într-un mediu web real.
Chiar și multe modele de Antiphishing funcționează prin compararea URL-urilor, titlurilor, linkurilor, casetelor de autentificare, informațiilor despre drepturile de autor, termenilor confidențiali, informațiilor motoarelor de căutare și chiar a logo-urilor mărcilor site-urilor web, și s-a demonstrat că pot fi folosite pentru a găsi site-uri de phishing. În ultimii ani, s-a acordat mai multă atenție caracteristicilor de înșelăciune vizuală și caracteristicilor de evaluare. Dar nu au fost suficient de puternice pentru a spune dacă un site este un site de phishing.
“Peste 98% din site-urile de phishing folosesc nume de domenii false,” spune APWG. Pentru modelele de antiphishing, cercetătorii folosesc informații din șirul URL. Cu toate acestea, obținerea informațiilor din spatele numelui de domeniu, cum ar fi înregistrarea și rezoluția domeniului, este de asemenea foarte importantă pentru detectarea phishingului. Aceste informații pot arăta adesea dacă un nume de domeniu este permis să ofere servicii legate de o marcă. Așadar, sarcina principală a cercetătorilor în domeniul antiphishing este să găsească caracteristici eficiente. Ei fac acest lucru analizând atacurile de inginerie socială și propunând un cadru de caracteristici complet și ușor de înțeles care acoperă nu doar toate aspectele atacurilor de phishing, ci și calitatea și relevanța conținutului web.
Detectarea phishingului în mai multe etape
Etapa 1: Filtrarea pe lista albă În această etapă, paginile web reale sunt separate de cele suspecte pe baza numelui de domeniu de phishing al site-ului pentru marca țintă.
Etapa 2: Aceasta este etapa de eliminare rapidă a facturilor false. Aceasta include eliminarea funcției de titlu fals, funcției de text fals și funcției vizuale false folosind un model de detectare. Ultimul pas este extragerea și combinarea funcțiilor de recunoaștere precisă a contrafacerii, furtului, afilierii, evaluării, instruirii și detectării modelelor folosind funcția CASE, care este o detectare a phishingului bazată pe instruire pe modele modificate.
În concluzie
Cu această abordare de oprire a phishingului, care se bazează pe detectarea la scară multiplă, vor exista 883 de atacuri de phishing asupra China Mobile, 86 asupra Bank of China, 19 asupra Facebook și 13 asupra Apple în 2022. demonstrând că modelul CASE acoperă spațiul de caracteristici care reflectă natura de înșelăciune a phishingului, asigurându-se că caracteristicile pot fi distinse și generalizate și oferind suport eficient pentru detectarea phishingului la nivel de caracteristică.

securitate
admin este redactor senior pentru Government Technology. Anterior a scris pentru PYMNTS și The Bay State Banner și deține o diplomă de licență în scriere creativă de la Carnegie Mellon. Ea locuiește în afara Bostonului.