โมเดลการตรวจจับเว็บไซต์ฟิชชิ่งแบบหลายขั้นตอนที่มีประสิทธิภาพ
มีนาคม 02, 2023 • ความปลอดภัย

ฟิชชิ่งเป็นวิธีที่พบมากที่สุดที่อาชญากรไซเบอร์ใช้ในการขโมยข้อมูลในปัจจุบัน และภัยคุกคามไซเบอร์นี้กำลังแย่ลงเรื่อย ๆ เนื่องจากมีรายงานเกี่ยวกับการรั่วไหลของข้อมูลส่วนตัวและการสูญเสียทางการเงินที่เกิดจากการโจมตีไซเบอร์ประเภทนี้เพิ่มขึ้นเรื่อย ๆ สิ่งสำคัญคือต้องจำไว้ว่าวิธีที่ ODS ตรวจจับฟิชชิ่งไม่ได้พิจารณาอย่างเต็มที่ว่าอะไรทำให้ฟิชชิ่งทำงานได้.
นอกจากนี้ โมเดลการตรวจจับทำงานได้ดีเพียงกับชุดข้อมูลจำนวนเล็กน้อยเท่านั้น พวกเขาจำเป็นต้องได้รับการปรับปรุงก่อนที่จะสามารถใช้ในสภาพแวดล้อมเว็บจริงได้ ด้วยเหตุนี้ ผู้ใช้จึงต้องการวิธีใหม่ ๆ ในการค้นหาเว็บไซต์ฟิชชิ่งอย่างรวดเร็วและแม่นยำ สำหรับเรื่องนี้ หลักการของวิศวกรรมสังคมเสนอจุดที่น่าสนใจที่สามารถใช้สร้างวิธีการที่มีประสิทธิภาพในการตรวจจับเว็บไซต์ฟิชชิ่งในขั้นตอนต่าง ๆ โดยเฉพาะบนเว็บจริง.
ประวัติของฟิชชิ่ง
จำไว้ว่าฟิชชิ่งเป็นประเภทหนึ่งของการโจมตีวิศวกรรมสังคม ซึ่งหมายความว่าแฮกเกอร์ใช้สัญชาตญาณธรรมชาติ ความไว้วางใจ ความกลัว และความโลภของผู้คนเพื่อหลอกลวงให้พวกเขาทำสิ่งที่ไม่ดี การวิจัยด้านความปลอดภัยทางไซเบอร์แสดงให้เห็นว่า ฟิชชิ่งเพิ่มขึ้น 350% ในช่วงกักกัน COVID-19. คาดว่าต้นทุนของฟิชชิ่งตอนนี้เป็น 1/4 ของต้นทุนของการโจมตีไซเบอร์แบบดั้งเดิม แต่รายได้เป็นสองเท่าของที่เคยเป็นในอดีต การโจมตีฟิชชิ่งทำให้ธุรกิจขนาดกลางเสียค่าใช้จ่ายเฉลี่ย $1.6 ล้านในการจัดการเพราะภัยคุกคามไซเบอร์นี้ทำให้การสูญเสียลูกค้าง่ายกว่าการได้ลูกค้า.
การโจมตีฟิชชิ่งสามารถมีลักษณะต่าง ๆ และมักใช้วิธีการหลายอย่างในการสื่อสารกับผู้คน เช่น อีเมล ข้อความ และโซเชียลมีเดีย ไม่ว่าช่องทางใดที่ใช้ ผู้โจมตีมักจะแกล้งเป็นธนาคารที่มีชื่อเสียง บริษัทบัตรเครดิต หรือเว็บไซต์อีคอมเมิร์ซเพื่อขู่ให้ผู้ใช้เข้าสู่ระบบเว็บไซต์ฟิชชิ่งและทำสิ่งที่พวกเขาจะเสียใจในภายหลัง หรือบังคับให้พวกเขาทำเช่นนั้น.
ตัวอย่างเช่น ผู้ใช้อาจได้รับข้อความทันทีอีกครั้งว่ามีปัญหากับบัญชีธนาคารของพวกเขาและถูกส่งไปยังลิงก์เว็บที่ดูคล้ายกับลิงก์ที่ธนาคารใช้มาก ผู้ใช้ไม่คิดมากเกี่ยวกับการใส่ชื่อผู้ใช้และรหัสผ่านของเขาลงในช่องที่อาชญากรให้มา เขาจดบันทึกข้อมูลของเธอซึ่งเขาใช้ในการเข้าสู่เซสชันของผู้ใช้.
ควรปรับปรุงอะไรในวิธีการป้องกันฟิชชิ่ง?
เพื่อที่จะตอบคำถามนี้ เราต้องเข้าใจกระบวนการฟิชชิ่งทั่วไป ซึ่งแสดงในรูปต่อไปนี้.
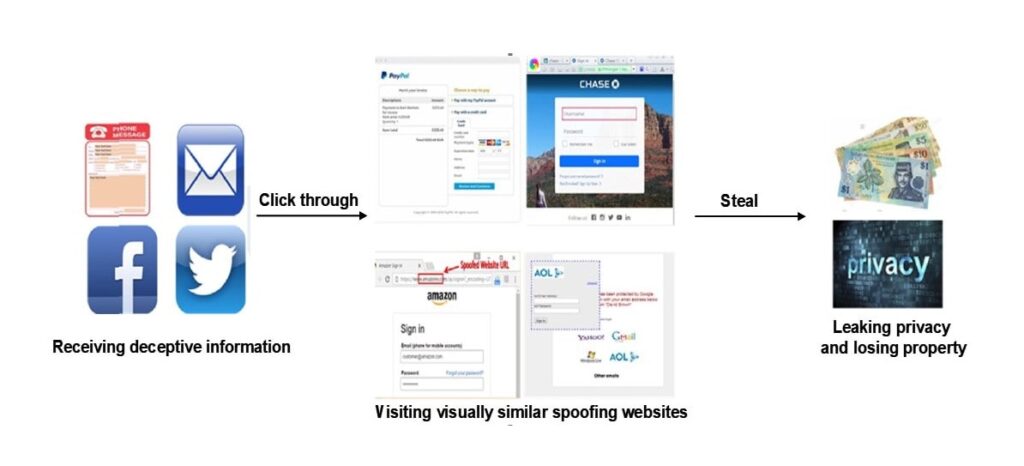
วิธีการป้องกันฟิชชิ่งที่เป็นกระแสหลักในปัจจุบันคือการตรวจจับเว็บไซต์ฟิชชิ่งโดยใช้การเรียนรู้ของเครื่อง วิธีการตรวจจับออนไลน์นี้ซึ่งอิงตามการเรียนรู้ทางสถิติเป็นวิธีการป้องกันฟิชชิ่งหลัก อย่างไรก็ตาม ความทนทานและประสิทธิภาพในสภาพแวดล้อมเว็บที่ซับซ้อนต้องได้รับการปรับปรุง ปัญหาหลักของวิธีการป้องกันฟิชชิ่งที่ใช้การเรียนรู้ของเครื่องสรุปไว้ด้านล่าง.
• มีการลบคุณสมบัติเพิ่มขึ้นโดยวิธีการป้องกันฟิชชิ่ง แต่ไม่ชัดเจนว่าทำไมคุณสมบัติเหล่านี้ถึงถูกลบ คุณสมบัติที่มีอยู่ไม่สะท้อนถึงธรรมชาติของฟิชชิ่งอย่างถูกต้อง ซึ่งใช้การปลอมแปลงเพื่อขโมยข้อมูลที่ละเอียดอ่อน เป็นผลให้ฟังก์ชันกลายเป็นที่ใช้ได้เฉพาะในบางสถานการณ์ที่จำกัดและเฉพาะเจาะจง เช่น ชุดข้อมูลเฉพาะหรือปลั๊กอินเบราว์เซอร์.
• อัลกอริทึมที่มีอยู่ปฏิบัติต่อเว็บไซต์ทั้งหมดในลักษณะเดียวกัน ส่งผลให้โมเดลทางสถิติไม่มีประสิทธิภาพ กล่าวอีกนัยหนึ่ง โมเดลไม่เหมาะสำหรับการใช้ในสภาพแวดล้อมเว็บจริงที่มีหน้าเว็บที่ซับซ้อนจำนวนมาก.
• ชุดข้อมูลส่วนใหญ่ไม่มีตัวอย่างเพียงพอ และความหลากหลายของตัวอย่างไม่ได้รับการพิจารณา นอกจากนี้ อัตราส่วนของตัวอย่างบวกต่อเชิงลบไม่สมจริง โดยทั่วไป โมเดลที่สร้างจากชุดข้อมูลประเภทนี้มีการฟิตเกินอย่างมาก และความทนทานของโมเดลจำเป็นต้องได้รับการปรับปรุง.
มีความก้าวหน้าอะไรในวิธีการป้องกันฟิชชิ่ง?
ในช่วงไม่กี่ปีที่ผ่านมา มีความพยายามที่จะคิดค้นวิธีการป้องกันฟิชชิ่งที่เชื่อถือได้และมีประสิทธิภาพในสภาพแวดล้อมเว็บจริง วิธีการนี้อิงตามอัลกอริทึมการเรียนรู้ของเครื่องทางสถิติที่ได้รับการปรับปรุงโดยการทดสอบต่อไปนี้:
• การใช้การวิเคราะห์รายละเอียดของรูปแบบการโจมตีฟิชชิ่งเพื่อหาฟังก์ชันทางสถิติสำหรับการป้องกันฟิชชิ่ง ฟังก์ชัน “ปลอมแปลง” “ความสัมพันธ์” “การขโมย” และ “การประเมิน” ถูกสกัดโดยโมเดลปัจจุบัน สิ่งเหล่านี้เรียกว่า “ฟังก์ชัน ”CASE". โมเดลนี้แสดงให้เห็นว่าวิศวกรรมสังคมถูกใช้ในการโจมตีฟิชชิ่งอย่างไรและเนื้อหาบนเว็บมีความเกี่ยวข้องและดีเพียงใด โมเดล CASE คำนึงถึงความจริงที่ว่าการปลอมแปลงเป็นส่วนหนึ่งของฟิชชิ่ง ทำให้มั่นใจได้ว่าคุณสมบัติสามารถแยกแยะและทั่วไปได้ และให้การสนับสนุนในระดับคุณสมบัติสำหรับการตรวจจับฟิชชิ่งที่มีประสิทธิภาพ.
• เนื่องจากเว็บไซต์ที่ถูกต้องและฟิชชิ่งไม่มีปริมาณการเข้าชมเท่ากัน โมเดลการตรวจจับปัจจุบันจึงอิงตามระบบความปลอดภัยหลายขั้นตอน แนวคิดเบื้องหลังโมเดลที่มีหลายขั้นตอนการตรวจจับคือการรับรอง “การกรองที่รวดเร็วและการรับรู้ที่แม่นยำ” ในระหว่างขั้นตอนการกรองอย่างรวดเร็ว เว็บไซต์ที่ถูกต้องจะถูกคัดออก การรับรู้ที่ถูกต้องจะทำโดยการเรียนรู้ตัวอย่างบวกและลบเฉพาะในช่วงที่เล็กลง ปรัชญาการตรวจจับนี้ทำให้มั่นใจได้ถึงประสิทธิภาพสูงด้วยเวลาการตรวจจับที่สั้นลง ซึ่งเป็นจริงมากขึ้นสำหรับเว็บจริง.
• โมเดลป้องกันฟิชชิ่งใหม่อิงตามการสร้างชุดข้อมูลที่ใกล้เคียงกับสภาพแวดล้อมเว็บจริงมากที่สุด โดยมีภาษาต่าง ๆ คุณภาพของเนื้อหา และแบรนด์ที่แตกต่างกัน นอกจากนี้ เนื่องจากการตรวจจับฟิชชิ่งเป็นปัญหาความไม่สมดุลของคลาส ตัวอย่างบวกและลบจำนวนมากจึงถูกคิดว่าผสมกัน ซึ่งทำให้ยากต่อการค้นหา สิ่งเหล่านี้ทั้งหมดทำให้ยากต่อการค้นหาเพื่อสร้างโมเดลการตรวจจับฟิชชิ่งที่มีประสิทธิภาพและสามารถใช้ในสภาพแวดล้อมเว็บจริงได้.
แม้ว่าโมเดลป้องกันฟิชชิ่งหลายรุ่นจะทำงานโดยการเปรียบเทียบ URL ชื่อเรื่อง ลิงก์ กล่องเข้าสู่ระบบ ข้อมูลลิขสิทธิ์ ข้อกำหนดที่เป็นความลับ ข้อมูลเครื่องมือค้นหา และแม้กระทั่งโลโก้ของแบรนด์เว็บไซต์ และได้แสดงให้เห็นว่าสามารถใช้ในการค้นหาเว็บไซต์ฟิชชิ่งได้ ในช่วงไม่กี่ปีที่ผ่านมา มีความสนใจมากขึ้นในคุณสมบัติการปลอมแปลงภาพและคุณสมบัติการประเมิน แต่พวกเขายังไม่แข็งแกร่งพอที่จะบอกได้ว่าไซต์เป็นไซต์ฟิชชิ่งหรือไม่.
“มากกว่า 98% ของเว็บไซต์ฟิชชิ่งใช้ชื่อโดเมนปลอม,” กล่าวโดย APWG สำหรับโมเดลป้องกันฟิชชิ่ง นักวิจัยใช้ข้อมูลจากสตริง URL อย่างไรก็ตาม การรับข้อมูลเบื้องหลังชื่อโดเมน เช่น การลงทะเบียนโดเมนและการแก้ไขปัญหา ก็มีความสำคัญอย่างยิ่งสำหรับการตรวจจับฟิชชิ่ง ข้อมูลนี้มักจะแสดงว่าชื่อโดเมนได้รับอนุญาตให้ให้บริการที่เกี่ยวข้องกับแบรนด์หรือไม่ ดังนั้น งานหลักของนักวิจัยป้องกันฟิชชิ่งคือการค้นหาคุณสมบัติที่มีประสิทธิภาพ พวกเขาทำเช่นนี้โดยการดูการโจมตีวิศวกรรมสังคมและเสนอกรอบคุณสมบัติที่สมบูรณ์และเข้าใจง่ายที่ครอบคลุมไม่เพียงแต่ทุกแง่มุมของการโจมตีฟิชชิ่ง แต่ยังรวมถึงคุณภาพและความเกี่ยวข้องของเนื้อหาเว็บด้วย.
การตรวจจับฟิชชิ่งหลายขั้นตอน
ขั้นตอนที่ 1: การกรองรายการขาว ในขั้นตอนนี้ หน้าเว็บจริงจะถูกแยกออกจากหน้าเว็บที่น่าสงสัยตามชื่อโดเมนฟิชชิ่งของเว็บไซต์สำหรับแบรนด์เป้าหมาย.
ขั้นตอนที่ 2: นี่คือขั้นตอนของการกำจัดบิลปลอมอย่างรวดเร็ว ซึ่งรวมถึงการกำจัดฟังก์ชันชื่อปลอม ฟังก์ชันข้อความปลอม และฟังก์ชันภาพปลอมโดยใช้โมเดลการตรวจจับ ขั้นตอนสุดท้ายคือการสกัดและรวมฟังก์ชันของการรับรู้ที่แม่นยำของการปลอมแปลง การขโมย ความสัมพันธ์ การประเมิน การฝึกอบรม และการตรวจจับโมเดลโดยใช้ฟังก์ชัน CASE ซึ่งเป็นการตรวจจับฟิชชิ่งที่อิงตามการฝึกอบรมโดยใช้โมเดลที่เปลี่ยนแปลง.
บทสรุป
ด้วยวิธีการหยุดฟิชชิ่งนี้ซึ่งอิงตามการตรวจจับหลายระดับ จะมีการโจมตีฟิชชิ่ง 883 ครั้งบน China Mobile, 86 ครั้งบน Bank of China, 19 ครั้งบน Facebook และ 13 ครั้งบน Apple ในปี 2022 แสดงให้เห็นว่าโมเดล CASE ครอบคลุมพื้นที่คุณสมบัติที่สะท้อนถึงธรรมชาติการปลอมแปลงของฟิชชิ่ง ทำให้มั่นใจได้ว่าคุณสมบัติสามารถแยกแยะและทั่วไปได้ และให้การสนับสนุนการตรวจจับฟิชชิ่งที่มีประสิทธิภาพในระดับคุณสมบัติ.

ความปลอดภัย
แอดมินเป็นนักเขียนอาวุโสของ Government Technology ก่อนหน้านี้เธอเคยเขียนบทความให้กับ PYMNTS และ The Bay State Banner และสำเร็จการศึกษาระดับปริญญาตรีสาขาการเขียนสร้างสรรค์จากมหาวิทยาลัยคาร์เนกีเมลลอน เธออาศัยอยู่ชานเมืองบอสตัน