Effektiv model til detektering af phishing-hjemmesider i flere trin
marts 02, 2023 • sikkerhed

Phishing er den mest almindelige metode for cyberkriminelle til at stjæle information i dag, og denne cybertrussel bliver værre, da flere og flere rapporter kommer ind om brud på privatlivets fred og økonomiske tab forårsaget af denne type cyberangreb. Det er vigtigt at huske, at den måde, ODS opdager phishing på, ikke fuldt ud ser på, hvad der får phishing til at fungere.
Desuden fungerer detektionsmodellerne kun godt på et lille antal datasæt. De skal forbedres, før de kan bruges i det virkelige webmiljø. På grund af dette ønsker brugerne nye måder til hurtigt og præcist at finde phishing-websteder. Til dette tilbyder principperne for social engineering interessante punkter, der kan bruges til at skabe effektive måder at opdage phishing-websteder på forskellige stadier, især på det virkelige web.
Historien om Phishing
Husk, at phishing er en almindelig type social engineering-angreb, hvilket betyder, at hackere bruger folks naturlige instinkter, tillid, frygt og grådighed til at narre dem til at gøre dårlige ting. Forskning i cybersikkerhed viser, at phishing steg med 350% under COVID-19 karantænen. Det anslås, at omkostningerne ved phishing nu er 1/4 af omkostningerne ved traditionelle cyberangreb, men indtægterne er dobbelt så høje som tidligere. Phishing-angreb koster mellemstore virksomheder i gennemsnit $1,6 millioner at håndtere, fordi denne cybertrussel gør det lettere at miste kunder end at vinde dem.
Phishing-angreb kan se forskellige ud og bruger normalt en række måder at kommunikere med folk på, såsom e-mail, tekstbeskeder og sociale medier. Uanset hvilken kanal der bruges, udgiver angribere sig ofte for at være kendte banker, kreditkortselskaber eller e-handelswebsteder for at skræmme brugere til at logge ind på phishing-siden og gøre ting, de senere vil fortryde, eller for at tvinge dem til at gøre det.
For eksempel kan en bruger igen få en øjeblikkelig besked om, at der er et problem med deres bankkonto og blive sendt til et weblink, der ligner meget det link, banken bruger. Brugeren tænker ikke to gange om at indtaste sit brugernavn og adgangskode i de felter, som kriminelle giver ham. Han noterer sig hendes oplysninger, som han derefter bruger til at få adgang til brugerens session.
Hvad bør forbedres i Antiphishing-metoder?
For at besvare dette spørgsmål skal vi forstå den typiske phishing-proces, som er vist i følgende figur.
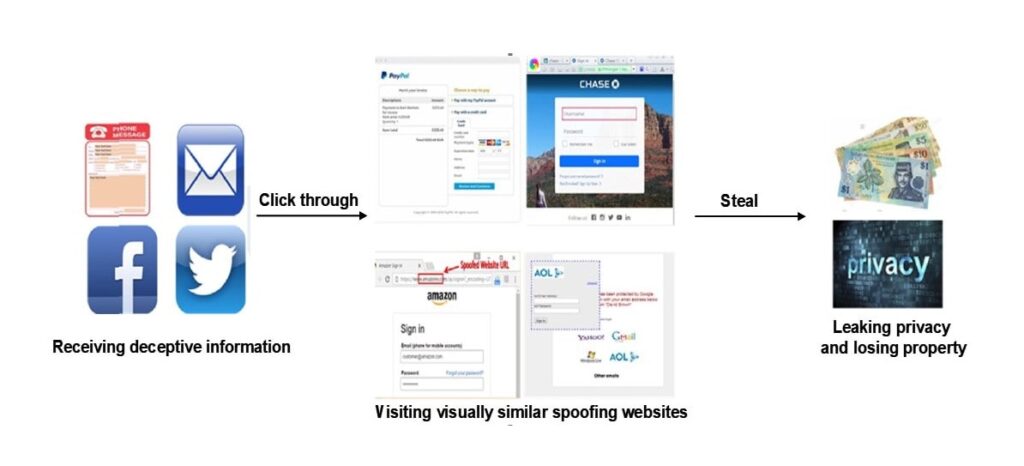
Den nuværende mainstream antiphishing-metode er maskinlæringsbaseret phishing-webstedsdetektion. Denne online detektionsmetode, som er baseret på statistisk læring, er den primære antiphishing-metode; dog skal dens robusthed og effektivitet i komplekse webmiljøer forbedres. De vigtigste problemer med maskinlæringsbaserede antiphishing-metoder er opsummeret nedenfor.
• Et stigende antal funktioner fjernes af antiphishing-metoder, men det er ikke klart, hvorfor disse funktioner fjernes. Eksisterende funktioner afspejler ikke nøjagtigt phishingens natur, som bruger spoofing til at stjæle følsomme oplysninger. Som et resultat bliver funktionerne kun gyldige i få begrænsede og specifikke scenarier, såsom specifikke datasæt eller en browser-plugin.
• Eksisterende algoritmer behandler alle websteder på samme måde, hvilket resulterer i, at den statistiske model er ineffektiv. Med andre ord er modellerne uegnede til brug i et virkeligt webmiljø med et stort antal komplekse websider.
• De fleste datasæt har ikke nok prøver, og mangfoldigheden af prøverne tages ikke i betragtning. Desuden er forholdet mellem positive og negative prøver ikke realistisk. Generelt har modeller bygget på denne slags datasæt meget overtilpasning, og modellernes robusthed skal forbedres.
Hvad har været fremskridtet i Antiphishing-metoder?
I de seneste år har folk forsøgt at udvikle en storstilet, pålidelig og effektiv anti-phishing-metode, der fungerer i et virkeligt webmiljø. Denne metode er baseret på statistiske maskinlæringsalgoritmer, der forbedres af følgende tests:
• Ved hjælp af en detaljeret analyse af mønsteret af phishing-angreb for at finde statistiske funktioner til anti-phishing. Funktionerne “forfalskning”, “tilknytning”, “tyveri” og “vurdering” udtrækkes alle af de nuværende modeller. Disse kaldes “CASE”-funktioner. Denne model viser, hvordan social engineering bruges i phishing-angreb, og hvor relevant og godt indholdet er på nettet. CASE-modellen tager højde for, at spoofing er en del af phishing, sikrer, at funktioner kan skelnes og generaliseres, og giver støtte på funktionsniveau til effektiv phishing-detektion.
• Fordi legitime og phishing-websteder ikke har den samme mængde trafik, er de nuværende detektionsmodeller baseret på et sikkerhedssystem i flere trin. Ideen bag modeller med flere detektionstrin er at sikre “hurtig filtrering og præcis genkendelse”. Under det hurtige filtertrin sorteres legitime websteder fra. Nøjagtig overvåget genkendelse udføres derefter ved at lære specifikke positive og negative prøver i et mindre område. Denne detektionsfilosofi sikrer høj ydeevne med en kortere detektionstid, hvilket er mere realistisk for det virkelige web.
• De nye Antiphishing-modeller er baseret på at bygge datasæt, der er så tæt som muligt på det virkelige webmiljø, med forskellige sprog, indholdskvaliteter og mærker. Desuden, da Phishing-detektion er et klasse-ubalanceret problem, menes mange positive og negative prøver nu at være blandet sammen, hvilket gør dem meget svære at finde. Alle disse ting gør det sværere at finde for at lave Antiphishing-detektion modeller, der fungerer godt og kan bruges i et virkeligt webmiljø.
Selv mange Antiphishing-modeller fungerer ved at sammenligne URL'er, titler, links, login-bokse, copyright-information, fortrolige vilkår, søgemaskineinformation og endda logoerne på webstedernes mærker, og det er blevet vist, at de kan bruges til at finde phishing-websteder. I de seneste år er der blevet lagt mere vægt på visuelle spoofing-funktioner og evalueringsfunktioner. Men de har ikke været stærke nok til at afgøre, om et websted er et Phishing-websted.
“Mere end 98% af phishing-websteder bruger falske domænenavne,” siger APWG. For antiphishing-modeller bruger forskere information fra URL-strengen. Det er dog også meget vigtigt for phishing-detektion at få informationen bag domænenavnet, såsom domæneregistrering og opløsning. Denne information kan ofte vise, om et domænenavn har lov til at tilbyde tjenester relateret til et mærke. Så den vigtigste opgave for antiphishing-forskere er at finde effektive funktioner. De gør dette ved at se på social engineering-angreb og foreslå en komplet og letforståelig funktionsramme, der dækker ikke kun alle aspekter af phishing-angreb, men også kvaliteten og relevansen af webindhold.
Multistage phishing-detektion
Trin 1: Hvidliste-filtrering På dette trin adskilles rigtige websider fra mistænkelige baseret på webstedets phishing-domænenavn for målbrandet.
Trin 2: Dette er stadiet for hurtigt at slippe af med falske regninger. Dette inkluderer at slippe af med den falske titelfunktion, den falske tekstfunktion og den falske visuelle funktion ved hjælp af en detektionsmodel. Det sidste trin er at udtrække og kombinere funktionerne for nøjagtig genkendelse af forfalskning, tyveri, tilknytning, evaluering, træning og detektion af modeller ved hjælp af CASE-funktionen, som er en træningsbaseret phishing-detektion baseret på ændrede modeller.
Som konklusion
Med denne tilgang til at stoppe phishing, som er baseret på multi-skala detektion, vil der være 883 phishing-angreb på China Mobile, 86 på Bank of China, 19 på Facebook og 13 på Apple i 2022. Dette demonstrerer, at CASE-modellen dækker funktionsrummet, der afspejler phishingens spoofing-natur, sikrer, at funktioner kan skelnes og generaliseres, og giver effektiv phishing-detektion støtte på funktionsniveau.

sikkerhed
admin er seniorskribent for Government Technology. Hun har tidligere skrevet for PYMNTS og The Bay State Banner og har en BA i kreativ skrivning fra Carnegie Mellon. Hun bor uden for Boston.