Modello efficiente di rilevamento dei siti di phishing a più fasi
Marzo 02, 2023 • sicurezza

Il phishing è il metodo più comune per i criminali informatici di rubare informazioni oggi, e questa minaccia informatica sta peggiorando man mano che arrivano sempre più segnalazioni di violazioni della privacy e perdite finanziarie causate da questo tipo di attacco informatico. È importante tenere a mente che il modo in cui ODS rileva il phishing non esamina completamente ciò che rende il phishing efficace.
Inoltre, i modelli di rilevamento funzionano bene solo su un numero limitato di set di dati. Devono essere migliorati prima di poter essere utilizzati nell'ambiente web reale. Per questo motivo, gli utenti vogliono nuovi modi per trovare rapidamente e accuratamente i siti di phishing. A tal fine, i principi dell'ingegneria sociale offrono punti interessanti che possono essere utilizzati per creare modi efficaci per individuare i siti di phishing in diverse fasi, soprattutto sul web reale.
La Storia del Phishing
Ricorda che il phishing è un tipo comune di attacco di ingegneria sociale, il che significa che gli hacker usano gli istinti naturali delle persone, la fiducia, la paura e l'avidità per ingannarli a fare cose sbagliate. La ricerca sulla sicurezza informatica mostra che il phishing è aumentato del 350% durante la quarantena COVID-19. Si stima che il costo del phishing sia ora 1/4 del costo degli attacchi informatici tradizionali, ma i ricavi sono il doppio rispetto al passato. Gli attacchi di phishing costano alle aziende di medie dimensioni una media di $1.6 milioni per affrontarli perché questa minaccia informatica rende più facile perdere clienti che guadagnarli.
Gli attacchi di phishing possono apparire diversi e di solito utilizzano diversi modi per comunicare con le persone, come email, messaggi di testo e social media. Indipendentemente dal canale utilizzato, gli aggressori spesso fingono di essere banche conosciute, società di carte di credito o siti di e-commerce per spaventare gli utenti a effettuare il login sul sito di phishing e fare cose di cui si pentiranno in seguito, o per costringerli a farlo.
Ad esempio, un utente potrebbe ricevere nuovamente un messaggio istantaneo che dice che c'è un problema con il suo conto bancario e viene inviato a un link web che assomiglia molto al link utilizzato dalla banca. L'utente non ci pensa due volte a inserire il suo nome utente e la password nei campi che il criminale gli fornisce. Prende nota delle sue informazioni, che poi utilizza per accedere alla sessione dell'utente.
Cosa dovrebbe essere migliorato nei metodi Antiphishing?
Per rispondere a questa domanda, dobbiamo comprendere il tipico processo di phishing, che è mostrato nella figura seguente.
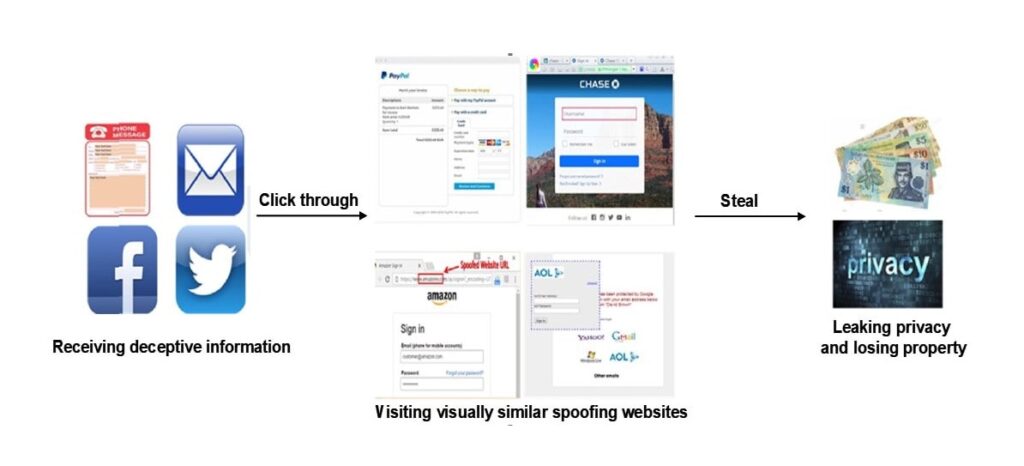
L'attuale metodo antiphishing mainstream è il rilevamento dei siti di phishing basato sull'apprendimento automatico. Questa modalità di rilevamento online, basata sull'apprendimento statistico, è il metodo antiphishing primario; tuttavia, la sua robustezza ed efficienza in ambienti web complessi devono essere migliorate. I principali problemi con i metodi antiphishing basati sull'apprendimento automatico sono riassunti di seguito.
• Un numero crescente di caratteristiche viene rimosso dai metodi antiphishing, ma non è chiaro perché queste caratteristiche vengano rimosse. Le caratteristiche esistenti non riflettono accuratamente la natura del phishing, che utilizza lo spoofing per rubare informazioni sensibili. Di conseguenza, le funzioni diventano valide solo in pochi scenari limitati e specifici, come set di dati specifici o un plugin del browser.
• Gli algoritmi esistenti trattano tutti i siti web allo stesso modo, risultando in un modello statistico inefficiente. In altre parole, i modelli non sono adatti per l'uso in un ambiente web reale con un gran numero di pagine web complesse.
• La maggior parte dei set di dati non ha abbastanza campioni, e la diversità dei campioni non viene presa in considerazione. Inoltre, il rapporto tra campioni positivi e negativi non è realistico. In generale, i modelli costruiti da questi tipi di set di dati hanno molto overfitting, e la robustezza dei modelli deve essere migliorata.
Qual è stato il progresso nei metodi Antiphishing?
Negli ultimi anni, le persone hanno cercato di sviluppare un metodo antiphishing su larga scala, affidabile ed efficace che funzioni in un ambiente web reale. Questo metodo si basa su algoritmi di apprendimento automatico statistico che sono migliorati dai seguenti test:
• Utilizzando un'analisi dettagliata del modello di attacchi di phishing per trovare funzioni statistiche per l'antiphishing. Le funzioni “contraffazione”, “affiliazione”, “furto” e “valutazione” sono tutte estratte dai modelli attuali. Queste sono chiamate “funzioni ”CASE". Questo modello mostra come l'ingegneria sociale viene utilizzata negli attacchi di phishing e quanto siano rilevanti e buoni i contenuti sul web. Il modello CASE tiene conto del fatto che lo spoofing è una parte del phishing, assicura che le caratteristiche possano essere distinte e generalizzate, e fornisce supporto a livello di caratteristiche per un rilevamento efficace del phishing.
• Poiché i siti web legittimi e di phishing non hanno la stessa quantità di traffico, i modelli di rilevamento attuali si basano su un sistema di sicurezza a più stadi. L'idea dietro i modelli con più stadi di rilevamento è garantire “filtraggio rapido e riconoscimento accurato”. Durante la fase di filtro rapido, i siti web legittimi vengono eliminati. Il riconoscimento accurato supervisionato viene quindi effettuato apprendendo campioni positivi e negativi specifici in un intervallo più piccolo. Questa filosofia di rilevamento garantisce alte prestazioni con un tempo di rilevamento più breve, che è più realistico per il web reale.
• I nuovi modelli Antiphishing si basano sulla costruzione di set di dati che siano il più vicino possibile all'ambiente web reale, con diverse lingue, qualità dei contenuti e marchi. Inoltre, poiché il rilevamento del phishing è un problema di squilibrio di classe, si pensa ora che molti campioni positivi e negativi siano mescolati, il che li rende molto difficili da trovare. Tutte queste cose rendono più difficile trovare al fine di creare modelli di rilevamento Antiphishing che funzionino bene e possano essere utilizzati in un ambiente web reale.
Anche molti modelli Antiphishing funzionano confrontando URL, titoli, link, caselle di login, informazioni sul copyright, termini riservati, informazioni sui motori di ricerca e persino i loghi dei marchi dei siti web, ed è stato dimostrato che possono essere utilizzati per trovare siti di phishing. Negli ultimi anni, è stata prestata maggiore attenzione alle caratteristiche di spoofing visivo e alle caratteristiche di valutazione. Ma non sono stati abbastanza forti per determinare se un sito è un sito di Phishing.
“Più del 98% dei siti di phishing utilizza nomi di dominio falsi,” dice l'APWG. Per i modelli antiphishing, i ricercatori utilizzano informazioni dalla stringa URL. Tuttavia, ottenere le informazioni dietro il nome di dominio, come la registrazione e la risoluzione del dominio, è anche molto importante per il rilevamento del phishing. Queste informazioni possono spesso mostrare se un nome di dominio è autorizzato a offrire servizi relativi a un marchio. Quindi, il compito principale dei ricercatori antiphishing è trovare caratteristiche efficaci. Lo fanno esaminando gli attacchi di ingegneria sociale e proponendo un quadro completo e facile da comprendere delle caratteristiche che copre non solo tutti gli aspetti degli attacchi di phishing ma anche la qualità e la rilevanza dei contenuti web.
Rilevamento del phishing a più stadi
Fase 1: Filtraggio della lista bianca In questa fase, le pagine web reali vengono separate da quelle sospette in base al nome di dominio di phishing del sito web per il marchio target.
Fase 2: Questa è la fase di eliminazione rapida delle fatture false. Questo include l'eliminazione della funzione del titolo falso, della funzione del testo falso e della funzione visiva falsa utilizzando un modello di rilevamento. L'ultimo passo è estrarre e combinare le funzioni di riconoscimento accurato di contraffazione, furto, affiliazione, valutazione, addestramento e rilevamento di modelli utilizzando la funzione CASE, che è un rilevamento di phishing basato sull'addestramento su modelli modificati.
In conclusione
Con questo approccio per fermare il phishing, che si basa sul rilevamento su scala multipla, ci saranno 883 attacchi di phishing su China Mobile, 86 su Bank of China, 19 su Facebook e 13 su Apple nel 2022. dimostrando che il modello CASE copre lo spazio delle caratteristiche che riflette la natura dello spoofing del phishing, assicurando che le caratteristiche possano essere distinte e generalizzate, e fornendo supporto efficace al rilevamento del phishing a livello di caratteristiche.

sicurezza
admin è una redattrice senior per Government Technology. In precedenza ha scritto per PYMNTS e The Bay State Banner e ha conseguito una laurea in scrittura creativa alla Carnegie Mellon. Risiede fuori Boston.