Efficiënt meerfasig detectiemodel voor phishingwebsites
maart 02, 2023 • beveiliging

Phishing is de meest voorkomende methode voor cybercriminelen om vandaag de dag informatie te stelen, en deze cyberdreiging wordt erger naarmate er steeds meer meldingen binnenkomen over privacylekken en financiële verliezen veroorzaakt door dit type cyberaanval. Het is belangrijk om in gedachten te houden dat de manier waarop ODS phishing detecteert niet volledig kijkt naar wat phishing effectief maakt.
Bovendien werken de detectiemodellen alleen goed op een klein aantal datasets. Ze moeten worden verbeterd voordat ze in de echte webomgeving kunnen worden gebruikt. Hierdoor willen gebruikers nieuwe manieren om snel en nauwkeurig phishingwebsites te vinden. Hiervoor bieden de principes van social engineering interessante punten die kunnen worden gebruikt om effectieve manieren te creëren om phishingwebsites in verschillende stadia te herkennen, vooral op het echte web.
De geschiedenis van phishing
Houd er rekening mee dat phishing een veelvoorkomend type social engineering-aanval is, wat betekent dat hackers gebruikmaken van de natuurlijke instincten, het vertrouwen, de angst en de hebzucht van mensen om hen te misleiden tot het doen van slechte dingen. Onderzoek naar cyberbeveiliging toont aan dat phishing met 350% is toegenomen tijdens de COVID-19-quarantaine. Men denkt dat de kosten van phishing nu 1/4 van de kosten van traditionele cyberaanvallen bedragen, maar de opbrengst is het dubbele van wat het in het verleden was. Phishingaanvallen kosten middelgrote bedrijven gemiddeld $1,6 miljoen om mee om te gaan, omdat deze cyberdreiging het gemakkelijker maakt om klanten te verliezen dan om ze te winnen.
Phishingaanvallen kunnen er anders uitzien en gebruiken meestal een aantal manieren om met mensen te communiceren, zoals e-mail, sms-berichten en sociale media. Ongeacht welk kanaal wordt gebruikt, doen aanvallers zich vaak voor als bekende banken, creditcardmaatschappijen of e-commercesites om gebruikers bang te maken om in te loggen op de phishingwebsite en dingen te doen waar ze later spijt van krijgen, of om hen daartoe te dwingen.
Een gebruiker kan bijvoorbeeld opnieuw een direct bericht ontvangen waarin staat dat er een probleem is met hun bankrekening en worden doorgestuurd naar een webkoppeling die erg lijkt op de koppeling die de bank gebruikt. De gebruiker denkt er niet twee keer over na om zijn gebruikersnaam en wachtwoord in te voeren in de velden die de crimineel hem geeft. Hij noteert haar informatie, die hij vervolgens gebruikt om toegang te krijgen tot de sessie van de gebruiker.
Wat moet worden verbeterd in Antiphishing-methoden?
Om deze vraag te beantwoorden, moeten we het typische phishingproces begrijpen, dat in de volgende afbeelding wordt weergegeven.
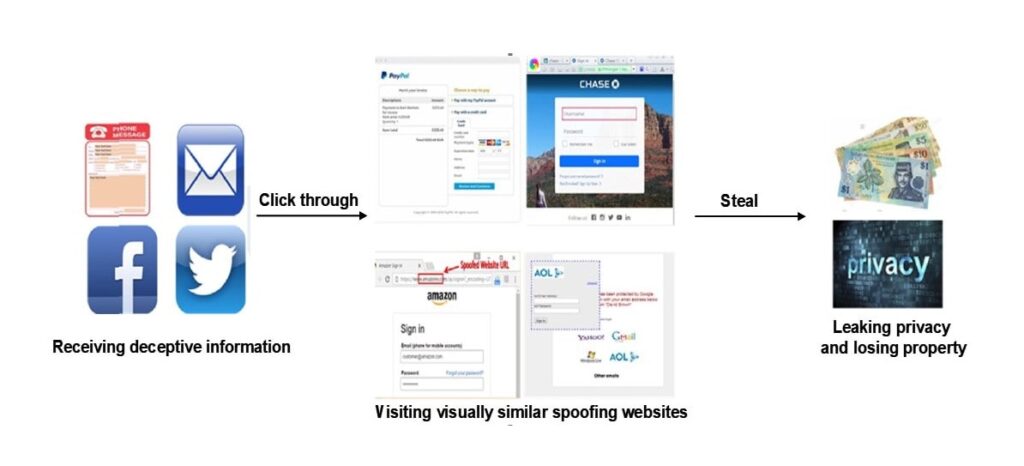
De huidige mainstream antiphishing-methode is op machine learning gebaseerde phishingwebsite-detectie. Deze online detectiemodus, die is gebaseerd op statistisch leren, is de primaire antiphishing-methode; echter, de robuustheid en efficiëntie ervan in complexe webomgevingen moet worden verbeterd. De belangrijkste problemen met op machine learning gebaseerde antiphishing-methoden worden hieronder samengevat.
• Een toenemend aantal functies wordt verwijderd door antiphishing-methoden, maar het is niet duidelijk waarom deze functies worden verwijderd. Bestaande functies weerspiegelen niet nauwkeurig de aard van phishing, dat spoofing gebruikt om gevoelige informatie te stelen. Als gevolg hiervan worden de functies alleen geldig in een paar beperkte en specifieke scenario's, zoals specifieke datasets of een browserplugin.
• Bestaande algoritmen behandelen alle websites op dezelfde manier, waardoor het statistische model inefficiënt is. Met andere woorden, de modellen zijn ongeschikt voor gebruik in een echte webomgeving met een groot aantal complexe webpagina's.
• De meeste datasets hebben niet genoeg voorbeelden, en de diversiteit van de voorbeelden wordt niet in aanmerking genomen. Ook is de verhouding van positieve tot negatieve voorbeelden niet realistisch. Over het algemeen hebben modellen die zijn gebouwd op dit soort datasets veel overfitting, en de robuustheid van de modellen moet worden verbeterd.
Wat is de vooruitgang in Antiphishing-methoden?
In de afgelopen jaren hebben mensen geprobeerd een grootschalige, betrouwbare en effectieve anti-phishing-methode te ontwikkelen die werkt in een echte webomgeving. Deze methode is gebaseerd op statistische machine learning-algoritmen die worden verbeterd door de volgende tests:
• Het gebruik van een gedetailleerde analyse van het patroon van phishingaanvallen om statistische functies voor anti-phishing te vinden. De functies “vervalsing”, “affiliatie”, “diefstal” en “beoordeling” worden allemaal geëxtraheerd door de huidige modellen. Deze worden genoemd “CASE”-functies. Dit model laat zien hoe social engineering wordt gebruikt in phishingaanvallen en hoe relevant en goed de inhoud op het web is. Het CASE-model houdt rekening met het feit dat spoofing een onderdeel is van phishing, zorgt ervoor dat functies kunnen worden onderscheiden en gegeneraliseerd, en biedt ondersteuning op functieniveau voor effectieve phishingdetectie.
• Omdat legitieme en phishingwebsites niet dezelfde hoeveelheid verkeer hebben, zijn huidige detectiemodellen gebaseerd op een meerfasig beveiligingssysteem. Het idee achter modellen met meerdere detectiefasen is om “snelle filtering en nauwkeurige herkenning” te garanderen. Tijdens de snelle filterfase worden legitieme websites eruit gefilterd. Nauwkeurige begeleide herkenning wordt vervolgens gedaan door specifieke positieve en negatieve voorbeelden in een kleiner bereik te leren. Deze detectiefilosofie zorgt voor hoge prestaties met een kortere detectietijd, wat realistischer is voor het echte web.
• De nieuwe Antiphishing-modellen zijn gebaseerd op het bouwen van datasets die zo dicht mogelijk bij de echte webomgeving liggen, met verschillende talen, inhoudskwaliteiten en merken. Ook omdat phishingdetectie een klasse-imbalanceprobleem is, wordt nu gedacht dat veel positieve en negatieve voorbeelden door elkaar gehaald worden, waardoor ze erg moeilijk te vinden zijn. Al deze dingen maken het moeilijker om Antiphishing-detectiemodellen te maken die goed werken en kunnen worden gebruikt in een echte webomgeving.
Zelfs veel Antiphishing-modellen werken door URL's, titels, links, inlogvakken, copyrightinformatie, vertrouwelijke termen, zoekmachine-informatie en zelfs de logo's van de merken van de websites te vergelijken, en het is aangetoond dat ze kunnen worden gebruikt om phishingwebsites te vinden. In de afgelopen jaren is er meer aandacht besteed aan visuele spoofing-functies en evaluatiefuncties. Maar ze zijn niet sterk genoeg geweest om te bepalen of een site een phishing-site is.
“Meer dan 98% van de phishingwebsites gebruiken valse domeinnamen,” zegt de APWG. Voor antiphishing-modellen gebruiken onderzoekers informatie uit de URL-string. Het verkrijgen van de informatie achter de domeinnaam, zoals domeinregistratie en resolutie, is echter ook erg belangrijk voor phishingdetectie. Deze informatie kan vaak aantonen of een domeinnaam is toegestaan om diensten aan te bieden die verband houden met een merk. Dus de belangrijkste taak van antiphishing-onderzoekers is om effectieve functies te vinden. Ze doen dit door te kijken naar social engineering-aanvallen en een compleet en gemakkelijk te begrijpen functiekader voor te stellen dat niet alleen alle aspecten van phishingaanvallen dekt, maar ook de kwaliteit en relevantie van webinhoud.
Meerfasige phishingdetectie
Fase 1: Whitelist-filtering In deze fase worden echte webpagina's gescheiden van verdachte op basis van de phishingdomeinnaam van de website voor het doelmerk.
Fase 2: Dit is de fase van het snel verwijderen van valse facturen. Dit omvat het verwijderen van de valse titelfunctie, de valse tekstfunctie en de valse visuele functie met behulp van een detectiemodel. De laatste stap is het extraheren en combineren van de functies van nauwkeurige herkenning van vervalsing, diefstal, affiliatie, evaluatie, training en detectie van modellen met behulp van de CASE-functie, die een op training gebaseerde phishingdetectie is op basis van gewijzigde modellen.
Conclusie
Met deze aanpak om phishing te stoppen, die is gebaseerd op detectie op meerdere schalen, zullen er in 2022 883 phishingaanvallen zijn op China Mobile, 86 op Bank of China, 19 op Facebook en 13 op Apple. Dit toont aan dat het CASE-model de functieruimte dekt die de spoofing-aard van phishing weerspiegelt, ervoor zorgt dat functies kunnen worden onderscheiden en gegeneraliseerd, en effectieve phishingdetectie-ondersteuning biedt op functieniveau.

beveiliging
admin is senior staff writer voor Government Technology. Ze schreef eerder voor PYMNTS en The Bay State Banner en heeft een B.A. in creatief schrijven van Carnegie Mellon. Ze woont buiten Boston.