Effektiv modell för upptäckt av nätfiskewebbplatser i flera steg
mars 02, 2023 • säkerhet

Phishing är den vanligaste metoden för cyberbrottslingar att stjäla information idag, och detta cyberhot blir värre när fler och fler rapporter kommer in om integritetsläckor och ekonomiska förluster orsakade av denna typ av cyberattack. Det är viktigt att komma ihåg att sättet ODS upptäcker phishing inte fullt ut tittar på vad som gör phishing effektivt.
Dessutom fungerar detektionsmodellerna bara bra på ett litet antal datamängder. De behöver förbättras innan de kan användas i den verkliga webbmiljön. På grund av detta vill användare ha nya sätt att snabbt och exakt hitta phishing-webbplatser. För detta erbjuder principerna för social ingenjörskonst intressanta punkter som kan användas för att skapa effektiva sätt att upptäcka phishing-sajter i olika stadier, särskilt på den verkliga webben.
Historien om Phishing
Kom ihåg att phishing är en vanlig typ av social ingenjörsattack, vilket innebär att hackare utnyttjar människors naturliga instinkter, förtroende, rädsla och girighet för att lura dem att göra dåliga saker. Forskning om cybersäkerhet visar att phishing ökade med 350% under COVID-19-karantänen. Det anses att kostnaden för phishing nu är 1/4 av kostnaden för traditionella cyberattacker, men intäkterna är dubbelt så höga som tidigare. Phishing-attacker kostar medelstora företag i genomsnitt $1,6 miljoner att hantera eftersom detta cyberhot gör det lättare att förlora kunder än att vinna dem.
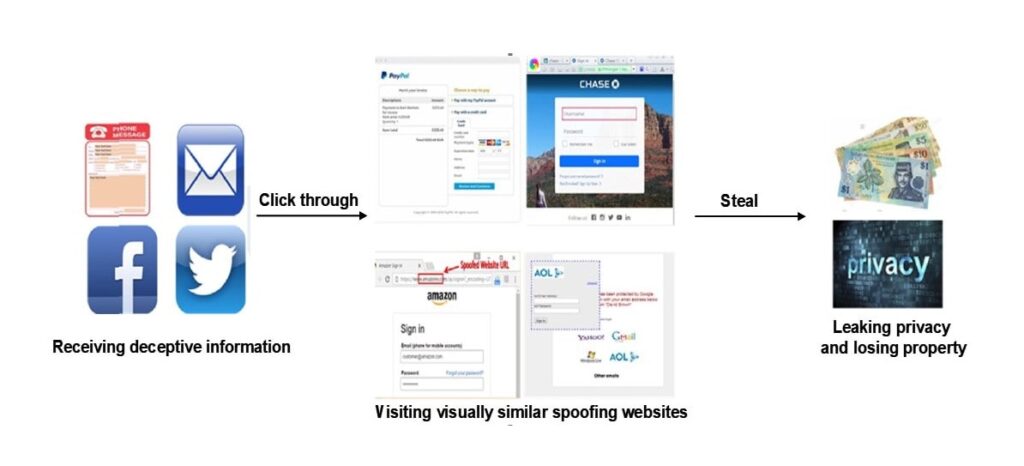
Phishing-attacker kan se olika ut och använder vanligtvis ett antal sätt att kommunicera med människor, som e-post, textmeddelanden och sociala medier. Oavsett vilken kanal som används, låtsas angripare ofta vara kända banker, kreditkortsföretag eller e-handelsplatser för att skrämma användare att logga in på phishing-sajten och göra saker de senare kommer att ångra, eller för att tvinga dem att göra det.
Till exempel kan en användare återigen få ett omedelbart meddelande som säger att det finns ett problem med deras bankkonto och skickas till en webblänk som ser mycket ut som länken banken använder. Användaren tvekar inte att skriva in sitt användarnamn och lösenord i de fält som brottslingen ger honom. Han noterar hennes information, som han sedan använder för att komma in i användarens session.
Vad bör förbättras i Antiphishing-metoder?
För att svara på denna fråga måste vi förstå den typiska phishing-processen, som visas i följande figur.
Den nuvarande mainstream-antiphishing-metoden är maskininlärningsbaserad phishing-webbplatsdetektion. Detta online-detekteringsläge, som är baserat på statistisk inlärning, är den primära antiphishing-metoden; dock måste dess robusthet och effektivitet i komplexa webbmiljöer förbättras. De viktigaste problemen med maskininlärningsbaserade antiphishing-metoder sammanfattas nedan.
• Ett ökande antal funktioner tas bort av antiphishing-metoder, men det är inte klart varför dessa funktioner tas bort. Befintliga funktioner återspeglar inte exakt phishingens natur, som använder spoofing för att stjäla känslig information. Som ett resultat blir funktionerna giltiga endast i några få begränsade och specifika scenarier, såsom specifika datamängder eller ett webbläsarplugin.
• Befintliga algoritmer behandlar alla webbplatser på samma sätt, vilket resulterar i att den statistiska modellen är ineffektiv. Med andra ord är modellerna olämpliga för användning i en verklig webbmiljö med ett stort antal komplexa webbsidor.
• De flesta datamängder har inte tillräckligt med prover, och mångfalden av proverna tas inte i beaktande. Dessutom är förhållandet mellan positiva och negativa prover inte realistiskt. I allmänhet har modeller byggda från dessa typer av datamängder mycket överanpassning, och modellernas robusthet behöver förbättras.
Vad har varit framstegen i Antiphishing-metoder?
Under de senaste åren har man försökt komma fram till en storskalig, pålitlig och effektiv antiphishing-metod som fungerar i en verklig webbmiljö. Denna metod är baserad på statistiska maskininlärningsalgoritmer som förbättras av följande tester:
• Använda en detaljerad analys av mönstret för phishing-attacker för att hitta statistiska funktioner för antiphishing. Funktionerna “förfalskning”, “affiliation”, “stöld” och “utvärdering” extraheras alla av de nuvarande modellerna. Dessa kallas “CASE”-funktioner. Denna modell visar hur social ingenjörskonst används i phishing-attacker och hur relevant och bra innehållet är på webben. CASE-modellen tar hänsyn till att spoofing är en del av phishing, säkerställer att funktioner kan särskiljas och generaliseras, och ger stöd på funktionsnivå för effektiv phishing-detektion.
• Eftersom legitima och phishing-webbplatser inte har samma mängd trafik, är nuvarande detektionsmodeller baserade på ett säkerhetssystem i flera steg. Idén bakom modeller med flera detektionssteg är att säkerställa “snabb filtrering och korrekt igenkänning”. Under det snabba filtreringssteget rensas legitima webbplatser bort. Korrekt övervakad igenkänning görs sedan genom att lära sig specifika positiva och negativa prover i ett mindre omfång. Denna detektionsfilosofi säkerställer hög prestanda med kortare detektionstid, vilket är mer realistiskt för den verkliga webben.
• De nya Antiphishing-modellerna är baserade på att bygga datamängder som är så nära som möjligt den verkliga webbmiljön, med olika språk, innehållskvaliteter och varumärken. Dessutom, eftersom Phishing-detektion är ett klassobalansproblem, anses nu många positiva och negativa prover vara sammanblandade, vilket gör dem mycket svåra att hitta. Alla dessa saker gör det svårare att hitta för att göra Antiphishing-detekteringsmodeller som fungerar bra och kan användas i en verklig webbmiljö.
Även många Antiphishing-modeller fungerar genom att jämföra URL:er, titlar, länkar, inloggningsrutor, upphovsrättsinformation, konfidentiella villkor, sökmotorinformation och till och med logotyperna för webbplatsernas varumärken, och det har visat sig att de kan användas för att hitta phishing-webbplatser. Under de senaste åren har mer uppmärksamhet ägnats åt visuella spoofing-funktioner och utvärderingsfunktioner. Men de har inte varit starka nog för att avgöra om en webbplats är en Phishing-sajt.
“Mer än 98% av phishing-webbplatser använder falska domännamn,” säger APWG. För antiphishing-modeller använder forskare information från URL-strängen. Men att få informationen bakom domännamnet, såsom domänregistrering och upplösning, är också mycket viktigt för phishing-detektion. Denna information kan ofta visa om ett domännamn har tillstånd att erbjuda tjänster relaterade till ett varumärke. Så den huvudsakliga uppgiften för antiphishing-forskare är att hitta effektiva funktioner. De gör detta genom att titta på sociala ingenjörsattacker och föreslå en komplett och lättförståelig funktionsram som täcker inte bara alla aspekter av phishing-attacker utan också kvaliteten och relevansen av webbinnehåll.
Multistegs phishing-detektion
Steg 1: Vitlista-filtrering I detta skede separeras riktiga webbsidor från misstänkta baserat på webbplatsens phishing-domännamn för målmärket.
Steg 2: Detta är stadiet för att snabbt bli av med falska räkningar. Detta inkluderar att bli av med den falska titelfunktionen, den falska textfunktionen och den falska visuella funktionen med hjälp av en detektionsmodell. Det sista steget är att extrahera och kombinera funktionerna för korrekt igenkänning av förfalskning, stöld, affiliation, utvärdering, träning och detektion av modeller med hjälp av CASE-funktionen, som är en träningsbaserad phishing-detektion baserad på ändrade modeller.
Sammanfattningsvis
Med detta tillvägagångssätt för att stoppa phishing, som är baserat på multiskalig detektion, kommer det att finnas 883 phishing-attacker på China Mobile, 86 på Bank of China, 19 på Facebook och 13 på Apple år 2022. vilket visar att CASE-modellen täcker funktionsutrymmet som återspeglar phishingens spoofing-natur, säkerställer att funktioner kan särskiljas och generaliseras, och ger effektivt phishing-detekteringsstöd på funktionsnivå.

säkerhet
admin är en senior personalförfattare för Government Technology. Hon skrev tidigare för PYMNTS och The Bay State Banner och har en BA i kreativt skrivande från Carnegie Mellon. Hon är baserad utanför Boston.